Réseaux IP et Principes de l'Internet
Auteurs: Olivier Alphand, Andrzej Duda, Franck Rousseau, Maciej Korczynski
Rentrée 2017
Cette version est optimisée pour une lecture à l'écran, et quelques fonctionnalités devraient vous aider à vous retrouver dans le document : sur les écrans suffisamment larges, la table des matières s'affiche à gauche de l'écran. La section courante est mise en évidence, et les sections parcourues depuis que vous avez lancé votre navigateur apparaissent avec une couleur différente. Pour que votre navigateur se souvienne des sections visitées d'une fois sur l'autre, cliquez sur les liens dans la table des matières : les liens visités de cette manière changent de couleur.
Les éléments important sont mis en avant de cette façon.
Les exercices…
et leur solution, ainsi !
1 Couche réseau
Ce cours fournit les connaissances de base des réseaux TCP/IP. Dans cette partie, nous considérons la couche réseau.
1.1 Notions principales
Cette partie définit les éléments et principes de fonctionnement des réseaux à commutation de paquets.
1.1.1 Qu'est-ce qu'un réseau?
Un réseau informatique est une interconnexion des différents éléments qui permettent la communication de l'information numérique.
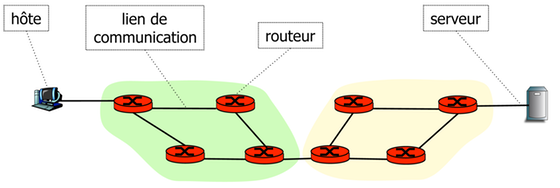
Les principaux éléments sont les suivants :
- Hôtes
- des ordinateurs ou des périphériques connectés au réseau via des liens de communication. Les hôtes qui fournissent des services utiles à d'autres dispositifs sont appelés serveurs. On utilise aussi le terme nœud pour désigner tout appareil connecté au réseau.
- Liens de communication
- (ou liaisons) qui permettent la propagation de signaux qui encodent l'information numérique. Les liens peuvent utiliser différents types de supports de communication (médium de transmission) tels que des câbles en cuivre, fibres optiques, ondes radio.
- Routeurs
- ce sont des dispositifs de relayage de paquets entre des liens de communication.
L'interconnexion des routeurs et des liens de communication permet d'assurer la communication entre des hôtes et des serveurs.
Les réseaux offrent la possibilité de communiquer par la résolution de deux problèmes principaux :
- Communication avec tout le monde — comment faire communiquer n'importe quelle paire d'hôtes ou de serveurs ?
- Communication partout — comment obtenir la possibilité de communication sur de longues distances et partout dans le monde?
Comment faire communiquer n'importe quelle paire d'hôtes ou de serveurs ?
Le maillage complet de tous les hôtes n'est pas possible pour un grand nombre d'hôtes, parce que le nombre de liens de communication nécessaires est \(n (n-1) / 2\) pour \(n\) hôtes. Les routeurs offrent la connectivité entre tous les hôtes avec un maillage partiel (interconnexion incomplète) qui nécessite un nombre limité des liens de communication.
Comment obtenir la possibilité de communication sur de longues distances ?
Nous pouvons couvrir de grandes espaces avec des liens de communication de longues distances et un maillage partiel des routeurs et des liens de communication.
1.1.2 Commutation de paquets
L'information numérique transmise sur le réseau de données est structurée en blocs appelés paquets. Un paquet contient un en-tête avec une certaine information de contrôle, par exemple les adresses source et destination, et une charge utile de données – les informations à transmettre.
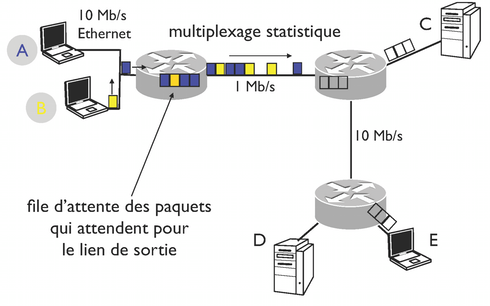
Les routeurs relayent des paquets de données entre un hôte source et un hôte de destination en effectuant la commutation de paquets : un routeur reçoit un paquet sur un lien, recherche dans la table de routage une entrée correspondant à la destination pour trouver le lien sur lequel il transmet le paquet vers le routeur suivant sur le chemin vers la destination.
Quel est le principe de la commutation de paquets ?
Un routeur reçoit un paquet sur un lien, il parcourt la table de routage pour trouver le lien sur lequel il émet le paquet vers le routeur suivant sur le chemin vers la destination.
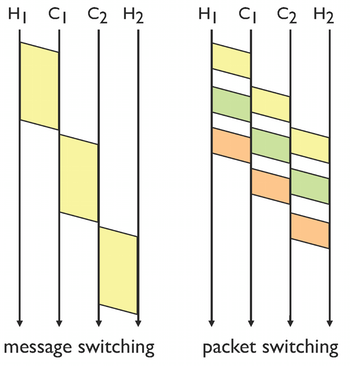
Pourquoi la commutation de paquets entraîne un retard inférieur au cas de la commutation de messages ?
En commutation de paquets, un message est divisé en paquets de taille limites. Leur transfert à travers plusieurs routeurs résulte en un délai plus petit. Si la taille de paquet est plus petite, l'amélioration du délai est plus marquée, mais la taille de paquet plus petite augmente aussi le surcoût lié à l'existence d'un en-tête dans le paquet ce qui signifie, qu'il existe une taille de paquet optimale.
1.1.3 Qu'est-ce que l'Internet ?
L'Internet est une interconnexion à grande échelle de routeurs et de liens de communication qui assurent une connectivité mondiale. Les routeurs fonctionnent selon le principe de commutation de paquets.
Les hôtes se connectent au premier routeur offrant la connectivité Internet à l'aide d'un réseau d'accès. Il existent différents types de réseaux d'accès : réseaux locaux comme Ethernet, lignes ADSL ou réseaux locaux sans fil tels que Wi-Fi (802.11).
Un système autonome (AS) est un ensemble de routeurs et des liens sous le contrôle d'un opérateur de réseau pour le compte d'une entité administrative unique avec une politique de routage unique. L'interconnexion des systèmes autonomes constitue l'Internet global.
Les systèmes autonomes échangent des paquets aux points d'échange Internet (Internet Exchange Points - IXP) – les réseaux locaux à haut débit reliant les routeurs de bordure des systèmes autonomes.
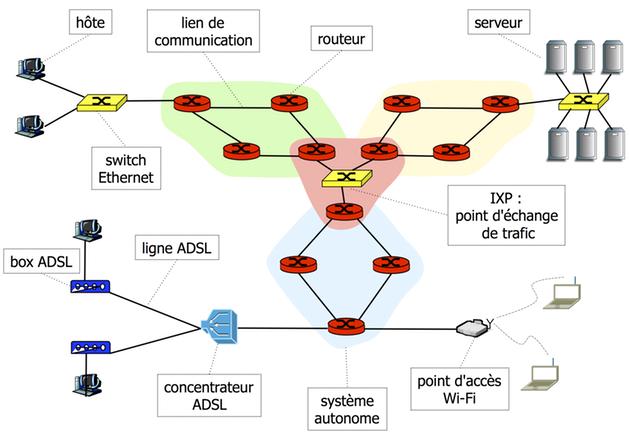
Le protocole d'Internet (Internet Protocol - IP) définit les principes de la communication sur l'Internet : le format des paquets et des adresses d'hôtes, et la commutation de paquets au niveau des routeurs.
Qu'est-ce qu'un hôte Internet?
Un ordinateur ou un périphérique connecté à l'Internet.
1.1.4 Performance de protocoles
La performance de protocoles concerne principalement le débit et le délai.
1.1.4.1 Débit binaire (bande passante, Bandwidth, Bit Rate, Throughput)
Le débit binaire de communication est le nombre de bits transmis par unité de temps.
Les unités:
- bit/s - b/s, kb/s = \(10^3\) b/s, Mb/s = \(10^6\) b/s, Gb/s=\(10^9\) b/s ;
- kb/s veut dire 1000 b/s et non 1024 b/s, 1 kB/s = 1000 Bytes/s = 8000 b/s.
Par abus de langage, le terme bande passante est aussi fréquemment utilisé pour désigner le débit dans le contexte de réseaux (au lieu de la largeur d'une bande de fréquence dans la contexte de transmissions). Exemple : le produit bande passante-délai qui correspond en fait au produit débit-délai.
Le débit binaire désigne la capacité de transmission de la couche PHY alors que le débit tout court ou débit utile se réfère plutôt à la capacité au niveau des couches supérieures : par exemple le débit utile au dessus de TCP = le nombre de bits transférés via une connexion TCP par unité de temps.
1.1.4.2 Latence ou délai
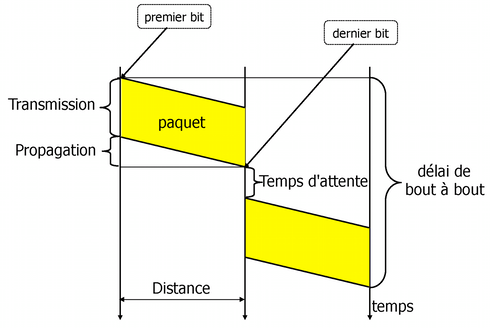
La latence ou le délai est l'intervalle de temps entre le début d'une transmission et sa fin observée à la réception. RTT (Round Trip Time - temps aller-retour) désigne le délai mesuré sur un hôte depuis l'instant d'émission jusqu'à la réception d'une réponse.
Pour calculer le délai (ou le temps de latence) :
\(D = T_p + T_t + T_w\), où
\(D\) est le délai, \(T_p\) est le temps de propagation, \(T_t\) le temps de transmission, et \(T_w\) le temps d'attente (habituellement négligé).
\(T_p = l / v\), où
\(l\) est la distance et \(v\) est la vitesse de propagation du signal :
- \(v = 2.3 \times 10 ^ 8\) m/s pour les câbles en cuivre ;
- \(v = 2 \times 10 ^ 8\) m/s pour le verre (fibres optique) ;
- \(v = 3 \times 10 ^ 8\) m/s, vitesse de la lumière dans le vide (satellites).
Une règle empirique utile pour calculer le temps de propagation est de compter \(5 \mu s\) par km, par exemple le temps de propagation pour la distance de 10 000 kilomètres est de 50 ms.
\(T_t = s / r\), où
\(s\) est le nombre de bits à transmettre (par exemple la taille du paquet) et \(r\) est le débit binaire.
Deux hôtes sont connectés à travers un routeur. La distance entre les hôtes est de 5000 km. Tous les liens dans le réseau ont un débit de 10 Mb/s. Hôte A envoie une série de 10 paquets de 1000 octets à B. Quel est le délai du transfert ?
\(11 \times 0,8 + 25 = 33,8\) ms
Deux hôtes sont connectés à travers deux routeurs. La distance entre les hôtes est de 10000 km. Tous les liens dans le réseau ont un débit de 10 Mb/s, sauf celui du milieu qui est à 1Mb/s. Un hôte envoie une série de 10 paquets de 1000 octets à B. Quel est le délai du transfert?
\(2 \times 0,8 + 10 \times 8 + 50 = 131,6\) ms
1.1.4.3 Produit bande passante - délai
Produit bande passante - délai est défini comme :
\(\beta = C \times RTT\) [bits],
où \(C\) est le débit binaire (ou bande passante en b/s) et \(RTT\) est le Temps Aller-Retour (Round Trip Time).
Le produit correspond à la quantité maximale de données pouvant être envoyées sur un lien ou sur un réseau avant de recevoir un accusé de réception ("le nombre de bits nécessaires pour remplir le tuyau").
Si l'expéditeur peut envoyer une quantité suffisante de données par rapport au produit bande passante-délai, alors l'utilisation de la liaison (ou le réseau) est élevée et le protocole de transfert réalise de bonnes performances.
Deux hôtes connectés via Internet obtiennent le débit de 1 Mb/s. La distance entre les hôtes est 10000 km. Un protocole de transfert de données utilise le principe de la fenêtre glissante : l'expéditeur peut envoyer \(W\) octets sans attendre un accusé de réception. Quelle est la taille de la fenêtre minimale pour obtenir de bonnes performances?
RTT \(=100\) ms. La taille de la fenêtre minimale correspond au produit bande passante - délai:
\(1\) Mb/s \(\times 100\) ms \(= 10^5\) bits \(= 12500\) octets.
1.2 Protocole Internet (IP)
Nous considérons ici le protocole d'acheminement de paquets entre n'importe quelle paire d'hôtes sur l'Internet. Ce protocole relève de la couche réseau (couche 3 dans le modèle OSI). Il y a deux versions principales du protocole IP actuellement en usage : IPv4 et IPv6. Leur principale différence est la taille d'adresses : 32 bits pour IPv4 et 128 bits en IPv6.
1.2.1 Adresses IPv4
Pour identifier les hôtes sur l'Internet, chaque hôte dispose d'une adresse IP unique. Plus précisément, chaque interface réseau dispose d'une adresse (un hôte ou un routeur peut avoir plusieurs interfaces réseau et plusieurs adresses).
Une adresse IPv4 est un nombre de 32 bits représenté par la notation
décimale pointée (dotted decimal), par exemple,
129.88.30.11. Chaque nombre décimal correspond à la valeur d'un
octet.
Comment peut-on identifier un hôte sur l'Internet ?
Par son adresse IPv4 ou IPv6.
Comment les adresses IPv4 sont codées ? Donner un exemple.
Par un nombre sur 32 bits représenté en notation décimale
pointée, p.ex. 129.88.30.11.
1.2.1.1 Sous-réseau (Subnetworks)
Un ensemble d'hôtes, également appelé sous-réseau (subnetwork ou subnet) est identifié par un préfixe unique.
Le préfixe de sous-réseau est formé par un nombre donné des bits les plus significatifs d'une adresse. La partie restante sur les bits les moins significatifs est un identificateur d'hôte sur un sous-réseau donné.
Exemple : 129.88.30.11 et 129.88.30.12 sont deux hôtes Internet
sur un sous-réseau identifié par le prefixe 129.88.30 sur 24
bits. Les valeurs 11 et 12 sont les identificateurs des hôtes sur
ce sous-réseau.
Donner un exemple d'un préfixe de sous-réseau codé sur 24 bits.
129.88.30.11 et 129.88.30.12
||129.88.30|| = 8 + 8 + 8 = 24 bits.
1.2.1.2 CIDR (Classless Interdomain Routing)
La notation CIDR (Classless Interdomain Routing) donne les
informations sur le préfixe et sa longueur en bits, par exemple
129.88.30/24.
Un préfixe CIDR désigne un bloc d'adresses IP en précisant la première adresse du bloc et sa longueur qui correspond à la longueur du champ pour identifier des hôtes sur un sous-réseau :
- IPv4 : \((32 - l)\),
- IPv6 : \((128 - l)\) où \(l\) est la longueur du préfixe.
Exemples :
129.88.30/24représente un bloc de 256 adresses (\(2^8\), \(8 = 32 - 24\)) dont la première adresse est129.88.30.0.129.88.30/23représente un bloc de 512 adresses (\(2^9\), \(9 = 32 - 23\)) dont la première adresse est129.88.30.0.
CIDR permet l'agrégation de blocs d'adresses : par exemple les blocs
129.88.30/24 et 129.88.31/24 peuvent être représentés comme un
bloc 129.88.30/23.
Que représente 129.88.80/22 ?
129.88.80/22 représente le préfixe de sous-réseau 129.88.80
sur 22 bits – un bloc de 1024 adresses dont la première adresse
est 129.88.80.0.
1.2.1.3 Agrégation
Supposons qu'un routeur a besoin de maintenir de l'information sur le
routeur suivant (next-hop) pour acheminer des paquets vers les
sous-réseaux 129.88.30/24 et 129.88.31/24 (on suppose que le
routeur next-hop est le même pour ces deux sous-réseaux).
Au lieu de maintenir deux entrées dans la table de routage pour ces
préfixes, le routeur peut les agréger en un seul préfixe
129.88.30/23 et maintenir une seule entrée dans les tables de
routage. De cette façon, les routeurs stockent moins d'information
dans les tables de routage.
Pourquoi l'agrégation d'adresses est importante ?
Parce qu'elle réduit la taille des tables de routage et minimise la consommation de ressources réseau.
Quel est l'agrégation des préfixes 197.132.116/24 et
197.132.117/24 ?
197.132.116/23
1.2.1.4 Netmask
Une autre façon de représenter des préfixes de sous-réseau est de spécifier une adresse et un masque de sous-réseau (netmask).
Un masque est un mot de 32 bits avec les \(n\) bits significatifs du
préfixe positionnés à 1. On représente le masque en notation décimale
pointée comme les adresses : par exemple 255.255.255.0 correspond au
préfixe /24.
L'information sur le préfixe est obtenu en appliquant l'operation logique AND entre une adresse et le masque de sous-réseau.
Exemple: 129.88.30.11 & b11111111111111111111111100000000 donne
129.88.30.00 qui correspond au préfixe 129.88.30/24.
Quel est le masque, le préfixe et l'identifiant d'hôte dans
l'adresse 129.132.119.77 en supposant la longueur de préfixe
/26 ?
Masque de sous-réseau: 255.255.255.192, préfixe:
129.132.119.64, id hôte : 0.0.0.13
Quel est le masque de sous-réseau correspondant au préfixe /4 ?
/22 ?
240.0.0.0
255.255.252.0
Quel est le préfixe correspondant à l'adresse 0.0.0.0 et le
netmask 0.0.0.0 ? À quoi correspond ce préfixe ?
/0 un bloc d'adresses de tout l'espace d'adressage IPv4. Ce
préfixe est utilisé dans les tables de routage pour désigné une
route par défaut - la route utilisée quand il n'y a pas d'autres
routes plus spécifiques.
1.2.1.5 Classes d'adresses
Avant l'introduction de la notation CIDR, la longueur des préfixes était fixe :
- Classe A -
/8 - plage d'adresses de
0.0.0.0à127.255.255.255, - Classe B -
/16 - plage d'adresses de
128.0.0.0à191.255.255.255, - Classe C -
/24 - plage d'adresses de
192.0.0.0à223.255.255.255.
Il y a aussi deux autres classes :
- Classe D
- plage d'adresses de
224.0.0.0à239.255.255.255pour IP Multicast, - Classe E
- plage d'adresses de
240.0.0.0à255.255.255.254, réservée.
1.2.1.6 Adresses spéciales
La référence est actuellemnt le RFC 6890 Special-Purpose IP Address Registries.
-
0.0.0.0 - désigne un hôte particulier, sur un sous-réseau donné, ne peut-être utilisé que comme source (quand l'hôte n'a pas encore son adresse définitive)
-
0.hostId - spécifiée l'hôte sur un sous-réseau donné
-
255.255.255.255 - broadcast limité, à tous les hôtes d'un sous-réseau (non transmis par les routeurs)
-
subnetId.all 1 - broadcast sur un sous-réseau donné
-
subnetId.all 0 - broadcast sur un sous-réseau donné, utilisé dans Unix BSD (obsolète)
-
127.x.x.x - boucle de test (loopback) (les paquets envoyés à cette adresse sont directement reçus par notre interface sans sortir sur le réseau)
-
10/8,172.16/12,192.168/16 - plage d'adresses réservées aux réseaux privés en usage interne (Intranet)
-
169.254/16 - adresse lien local (allouée automatiquement par zeroconf)
Lors de l'attribution des adresses à des hôtes dans un sous-réseau,
nous devons prendre en compte deux adresses qui ne sont pas
utilisables pour identifier des hôtes (subnetId.all 1 et
subnetId.all 0).
Un routeur connecté à un sous-réseau donné devra également avoir une adresse dans le sous-réseau (par convention, nous attribuons les nombres les plus élevés aux routeurs et les nombres les moins élevés à des hôtes).
Quelle est l'adresse de broadcast limité ?
255.255.255.255, limité, parce que les routeurs ne relayent pas
les paquets en broadcast.
Quelle est l'adresse de broadcast sur le sous-réseau 192.168/16
? et pour BSD ?
192.168.255.255, BSD : 192.168.0.0
Quelle est l'adresse de boucle de test (loopback) ? Exemple ?
127.x.x.x, exemple : 127.0.0.1
Quels sont les préfixes réservés aux Intranets?
10/8, 172.16/12, 192.168/16
Quel est le préfixe minimal (contenant le plus petit nombre d'adresses) requis pour l'attribution d'adresses à un sous-réseau avec 30 hôtes et 1 routeur ?
/26 : \(30 + 2 + 1 = 33\) adresses requises pour le sous-réseau,
la puissance de 2 supérieure est \(64 = 2^6\), donc la longueur de
préfixe est \(32 - 6 = 26\).
Quel est le nombre d'adresses utilisables (les adresses qui
peuvent être utilisées pour les identifiants d'hôtes ou routeurs
sur un sous-réseau donné) pour un préfixe /15 ?
\(2^{17}-2 = 131070\)
1.2.2 Relayage de paquets
Cette partie explique comment les routeurs relaient les paquets en fonction des adresses de destination.
1.2.2.1 Table de routage
Pour transmettre des paquets, un nœud (un hôte ou un routeur) a besoin des informations sur le routeur suivant (next-hop) où il doit envoyer un paquet de sorte qu'il atteigne la destination.
Une table de routage fournit cette information sous la forme suivante:
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Destination address | Netmask | Next-hop | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | 0.0.0.0 | 0.0.0.0 | 129.88.30.254 | | destinationAddr1 | 255.255.255.000 | 129.88.30.254 | | destinationAddr2 | 255.255.255.000 | 129.88.48.254 |
Nous pouvons interpréter l'information dans le tableau comme suit : si l'adresse de destination du paquet correspond à l'adresse de destination ou partage le même préfixe qu'une entrée dans la table, le paquet doit être transmis au next-hop associé.
La première entrée de la table est la route par défaut : elle correspond à toutes les destinations (toutes les adresses dans l'espace d'adressage IPv4).
Vous pouvez inspecter la table de routage avec une commande comme
netstat sous Unix ou route sous Windows.
Qu'est-ce qu'une route ?
Une séquence de routeurs entre l'hôte source et l'hôte de destination. Les entrées dans les tables de routage des routeurs définissent des routes.
Qu'est-ce qu'un next-hop ?
Le routeur auquel un nœud doit transmettre un paquet pour suivre une route.
Comment note-t-on la route par défaut (une entrée qui correspond à toutes les adresses) en notation CIDR ?
0/0 ou 0.0.0.0/0
Comment la route par défaut (une entrée qui correspond à toutes les adresses) est exprimée par une adresse et un masque de sous-réseau?
Adresse : 0.0.0.0 masque : 0.0.0.0
1.2.2.2 Table des interfaces physiques
La table donne des informations sur les préfixes des sous-réseaux auxquels le nœud est directement connecté. Il peut alors envoyer un paquet à un nœud quelconque sur un sous-réseau directement en encapsulant le paquet dans une trame d'une couche liaison telle que le réseau Ethernet, et envoyer la trame au nœud de destination sans passer par un nœud intermédiaire.
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Interface | Adresse IP | Netmask | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | en0 | 129.88.30.0 | 255.255.255.000 | | en1 | 129.88.48.0 | 255.255.255.000 |
Vous pouvez inspecter la table des interfaces physiques avec la
commande ifconfig sous Unix et ipconfig sous Windows.
1.2.2.3 Algorithme de relayage de paquets
Les hôtes et les routeurs suivent les règles ci-dessous pour
transmettre un paquet ayant destAddr comme adresse de
destination :
- Cas direct
- si
destAddrappartient au même préfixe que le préfixe d'une de nos interfaces réseau, envoyer le paquet directement à travers cette interface dans une trame de la couche liaison, - Cas indirect
- autrement, chercher dans la table de routage une
entrée correspondante à l'adresse
destAddrde destination pour trouver le prochain routeur (next-hop), et lui envoyer le paquet.
Plus spécifiquement :
Supposons que destAddr est l'adresse de destination du paquet à
transmettre, destinationAddr est une adresse dans la table de
routage.
- Cas 1
- il existe une route d'hôte pour
destAddr: pour chaque entrée dans la table de routage- si (
destinationAddr==destAddr)- envoyer le paquet au next-hop de l'entrée;
- sinon
- si (
- Cas 2
destAddrappartient à un sous-réseau directement connecté (= sur le lien) : pour chaque adresse IPAet le masqueNMde l'interface physique- si (
A&NM==destAddr&NM)- envoyer le paquet directement à
destAddr; - sinon
- envoyer le paquet directement à
- si (
- Cas 3
- il existe une route pour
destAddr: trouver dans la table de routage le plus long préfixe qui correspond àdestAddr- envoyer au next-hop de l'entrée;
- sinon
- Cas 4
- utilisation de la route par défaut :
- envoyer au next-hop de l'entrée par défaut.
Qu'est-ce qu'une route d'hôte ?
Une route qui correspond exactement à l'adresse de destination
(préfixe de /32).
Comment transmettre un paquet à un hôte sur un sous-réseau directement connecté ?
Envoyer le paquet à l'hôte de destination encapsulé dans une trame.
1.2.3 Détails d'IPv4 (RFC 791)
Cette partie fournit les détails du protocole IPv4.
1.2.3.1 Champs d'en-tête
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ |Version| IHL |Type of Service| Longueur totale | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Identification |Flags| Fragment Offset | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Time to Live | Protocole | Header Checksum | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Adresse Source | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Adresse Destination | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Options | Rembourrage | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
L'en-tête d'un paquet IPv4 a les champs suivants :
- Version
- quatre bits spécifiant la version du protocole. Deux versions coexistent actuellement: IPv4 et IPv6.
- Longueur de l'en-tête (IHL)
- l'en-tête de paquet peut contenir un nombre variable des options, donc nous avons besoin de l'information sur la longueur de l'en-tête. La longueur minimal sans options est 20 octets.
- TOS (Type of Service)
- ce champs précisait initialement le type de la Qualité de Service demandée pour le paquet : priorité (0 - 7, paquets normaux - paquets de contrôle), court délai (pour des applications comme telnet), haut débit (FTP), une haute fiabilité (SNMP), et faible coût (NNTP). Actuellement, le champ TOS est défini par DiffServ (Services différenciés) : un codepoint d'un octet qui donne une classe de QoS (Quality of Service) qui peuvt être : Expedited Forwarding (EF) - transfert accéléré pour minimiser le délai et la gigue, Assured Forwarding (AF) - quatre classes et trois priorités de perte de paquet (12 codepoints au total).
- Longueur
- longueur totale du paquet (en-tête et la charge utile de données) en octets. Le champ sur 16 bits permet de représenter la taille maximale théorique de 65 535 octets, mais les paquets IP sont généralement limités à la taille maximale de la trame de données au niveau de la couche liaison, par exemple si un hôte est connecté au réseau Ethernet, il pourra envoyer un paquet qui entre dans le champs de données d'une trame limitée à 1500 octets. Tous les sous-réseaux doivent pouvoir transporter des paquets de la taille minimale de 576 octets (512 octets de la charge utile de données et 64 octets de l'en-tête, 60 octets étant la taille de l'en-tête maximale).
- Identificateur
- utilisé dans la fragmentation. Une valeur unique attribuée par l'expéditeur pour assembler les fragments d'un paquet.
- Flags
- utilisés dans la fragmentation. Valeurs : bit 0 - réservé, doit être à zéro; bit 1: (DF) = 0 May Fragment, 1 = Don't Fragment; bit 2: (MF) 0 = Last Fragment, 1 = More Fragments.
- Fragment Offset
- utilisé dans la fragmentation. Il indique où se place un fragment dans le paquet reconstitué. Fragment offset est mesuré en unités de 8 octets (64 bits). Le premier fragment a l'offset de 0.
- Time-To-Live (TTL)
- indique le temps maximum pendant lequel le paquet est autorisé à rester dans l'Internet. Initialement, le temps etait mesuré en secondes, actuellement il correspond au nombre maximal de passage par des routeurs : chaque routeur diminue la durée de vie d'une unité. Si le TTL tombe à 0, le routeur enlève le paquet et envoie un paquet ICMP pour signaler la perte à la source.
- Protocole
- indique le protocole de niveau supérieur qui va traiter
les données de la charge utile. Exemples de valeurs :
6 - TCP,17 - UDP(cf. RFC 1700 pour tous les numéros possibles, RFC 3232 et iana.org). - Header Checksum
- bits de contrôle d'erreurs de transmission calculés sur l'en-tête uniquement. Comme certains champs de l'en-tête peuvent changer en cours de route (par exemple TTL), la somme de contrôle est recalculée et vérifiée à chaque routeur. Le champ de contrôle est le complément à 1 sur 16 bits de la somme arithmétique de tous les mots de 16 bits de l'en-tête. Pour ce calcul, la valeur de ce champ est égale à zéro.
- Adresses IP source et destination
- adresses IP sur 32 bits de la source et de la destination.
- Données utilise (payload)
- le champ contient les données à délivrer à la couche supérieure à la destination.
Pourquoi un champ longueur de l'en-tête ?
L'en-tête du paquet peut contenir un nombre variable d'options, donc nous avons besoin que sa longueur.
Comment connaître la taille de la charge utile de données?
La longueur totale du paquet - longueur de l'en-tête.
Pourquoi les paquets ont généralement une taille de 1500 octets?
Parce que ça correspond à la taille des données maximale d'une trame Ethernet.
Pourquoi un TTL est-il nécessaire ?
Pour détruire un paquet dans le cas d'une boucle de routage.
Comment un nœud sait quel protocole utiliser pour le traitement de la charge utile ?
La valeur du champ protocole.
1.2.3.2 Options de l'en-tête
- Strict Source Routing
- spécifie la liste de tous les routeurs sur la route vers la destination,
- Loose Source Routing
- spécifie la liste de certains routeurs sur la route vers la destination,
- Record Route
- utilisé pour tracer la route du paquet,
- Timestamp Route
- utilisé pour tracer la route du paquet et enregistrer les instants de passage par les routeurs,
- Router Alert
- notifie un routeur sur la route pour qu'il examine le contenu du paquet (utilisé par IGMP ou par RSVP pour traitement d'un paquet, cf. RFC 2113).
1.2.3.3 MTU (Maximum Transfert Unit), la taille maximale de transmission
MTU est la quantité maximale de données qu'une trame de couche liaison peut transporter. Le MTU d'un protocole de la couche liaison impose une limite à la longueur d'un paquet IP qui peut être transmis sur un lien (par exemple 1500 octets pour Ethernet).
1.2.3.4 Fragmentation
Quand un routeur veut transmettre un paquet IP sur un lien avec un MTU plus petit que la taille du paquet, il faut le fragmenter : on découpe un paquet large en une succession de paquets de taille suffisante pour traverser un lien. Les petits paquets sont appelés les fragments. La destination réassemble les fragments pour obtenir le paquet d'origine avant de le passer à la couche supérieure.
Exemple : un paquet de 1400 octets de données doit être fragmenté avant la transmission sur un lien avec le MTU de 620 octets.
L : Longueur, I : ID, MF: More Fragment flag, Of: Offset
Paquet initial :
1. L= 1420, I=567, MF=0, Of=0
Fragments :
1. L= 620, I=567, MF=1, Of=0 2. L= 620, I=567, MF=1, Of=75 (8xOf=600) 3. L= 220, I=567, MF=0, Of=150 (8xOf=1200)
À partir des informations dans l'en-tête, la destination peut réassembler le paquet original.
Un paquet de 1400 octets de données doit être fragmenté avant traverser un lien avec le MTU de 980 octets. Quelles sont les valeurs de L, I, Of ?
L=980, I=567, MF=1, Of=0L=460, I=567, MF=0, Of=120
1.2.3.5 ICMP (Internet Control Message Protocol)
Les routeurs et les hôtes utilisent le protocole ICMP pour signaler une erreur dans le traitement de paquets : un paquet peut ne pas atteindre sa destination, un routeur qui enlève un paquet à cause de TTL=0, ou quand un routeur notifie à un hôte d'envoyer le trafic sur une route plus courte.
Les messages ICMP sont encapsulés dans des paquets IP.
Les messages ICMP ont un champ type et code, et contiennent les huit premiers octets du paquet IP qui a provoqué la génération du message ICMP.
Principaux messages ICMP :
Type Code Description 0 0 Echo Reply (ping) 3 0-15 Destination Unreachable (network, host, protocol, port) 5 0-3 Redirect 8 0 Echo Request (ping) 11 0 Time Exceeded
Autres messages ICMP:
Type Code Description 9 0 Router Advertisement 10 0 Router Solicitation 12 0 Bad IP Header 13 0 Timestamp 14 0 Timestamp Reply 15 0 Information Request 16 0 Information Reply 17 0 Address Mask Request 18 0 Address Mask Reply
1.2.3.6 Commandes basées sur ICMP
La commande ping envoie un message ICMP Echo Request à une
destination qui répond avec un message ICMP Echo Reply.
La commande traceroute découvre les adresses IP des routeurs
intermédiaires sur la route vers une destination:
traceroutegénère un paquet IP avec un datagramme UDP vers une destination et le champ TTL = 1.- Le premier routeur sur la route vers la destination décrémente TTL qui devient 0, il détruit le paquet et envoie un message ICMP à la source.
- Ensuite,
traceroutegénère un paquet IP avec TTL = 2 pour découvrir le second routeur et ainsi de suite. - La destination répond avec un
ICMP Destination Unreachable, parce que le datagramme UDP utilise un numéro de port inexistant.
1.2.4 Address Resolution Protocol (ARP)
La transmission de paquets au next-hop sur une route vers la destination nécessite la connaissance de l'adresse MAC (également appelée adresse physique) correspondant à l'adresse IP du next-hop : le nœud doit connaitre cette adresse pour encapsuler le paquet dans une trame de la couche liaison telle qu'Ethernet par exemple. Pour délivrer un paquet à un réseau directement connecté, le nœud doit aussi connaitre l'adresse MAC de la destination.
Un nœud apprend dynamiquement l'adresse MAC d'un routeur ou d'un nœud de destination à l'aide du protocole de résolution d'adresse (ARP) : il envoie une requête ARP dans un paquet en broadcast à tous les hôtes/routeurs connectés à un réseau local donné. Le paquet comprend l'adresse IP pour laquelle nous voulons connaître l'adresse MAC. Le nœud qui reconnaît son adresse IP répond avec un paquet unicast contenant son adresse MAC.
ARP maintient une table avec les correspondances entre des adresses IP et les adresses MAC. Une entrée ARP est supprimée de la table après un intervalle (généralement 20 minutes).
Considérons un réseau avec trois hôtes : my.imag.fr
(10.0.1.1), dns.imag.fr (10.0.2.1), www.imag.fr
(10.0.3.1) reliés entre eux par un routeur qui a trois
interfaces : 10.0.1.254, 10.0.2.254,
10.0.3.254. my.imag.fr est connecté au routeur via un switch
(commutateur). Supposons que tous les hôtes sont correctement
configurés et leurs caches ARP sont vides. Un utilisateur exécute
la commande sur my.imag.fr : ping www. Donnez la séquence
temporelle de ce qui se passe dans le réseau en fournissant les
informations sur les adresses, les types de trames, adresses IP,
type de protocoles, et d'autres détails pertinents. Utilisez la
notation suivante pour les adresses Ethernet: E_10.0.1.1 est
l'adresse Ethernet de 10.0.1.1.
1. ARP 10.0.1.254 ? , E_10.0.1.1 à FF:FF:FF:FF:FF:FF 2. ARP 10.0.1.254 est E_10.0.1.254, E_10.0.1.254 à E_10.0.1.1 3. IP 10.0.1.1 à 10.0.2.1, E_10.0.1.1 à E_10.0.1.254, DNS sur UDP, www.imag.fr A? 4. ARP 10.0.2.1? , E_10.0.2.254 à FF:FF:FF:FF:FF:FF 5. ARP 10.0.2.1 est E_10.0.2.1 , E_10.0.2.1 à E_10.0.2.254 6. IP 10.0.1.1 à 10.0.2.1, E_10.0.2.254 à E_10.0.2.1 , DNS sur UDP, www.imag.fr A? 7. IP 10.0.2.1 à 10.0.1.1, E_10.0.2.1 à E_10.0.2.254, DNS sur UDP, www.imag.fr A 10.0.3.1 8. IP 10.0.2.1 à 10.0.1.1, E_10.0.1.254 à E_10.0.1.1 , DNS sur UDP, www.imag.fr A 10.0.3.1 9. IP 10.0.1.1 à 10.0.3.1, E_10.0.1.1 à E_10.0.1.254, ICMP Echo request 10. ARP 10.0.3.1? , E_10.0.3.1 à FF:FF:FF:FF:FF:FF 11. ARP 10.0.3.1 est E_10.0.3.1 , E_10.0.3.1 à E_10.0.3.254 12. IP 10.0.1.1 à 10.0.3.1, E_10.0.3.254 à E_10.0.3.1 , ICMP Echo request 13. IP 10.0.3.1 à 10.0.1.1, E_10.0.3.1 à E_10.0.3.254, ICMP Echo reply 14. IP 10.0.3.1 à 10.0.1.1, E_10.0.1.254 à E_10.0.1.1 , ICMP Echo reply
1.2.4.1 Format de message ARP
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Hardware Type | Protocol Type | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | HW@ Length | Proto@ Length | Opcode | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Sender Hard... | + +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | ware Address | Sender Proto... | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | col Address | Target Hard... | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ + | ware Address | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Target Protocol Address | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
1.2.4.2 Algorithme du protocole ARP
ARP Request sent
wait for reply
if received
put target information (MAC address) into the table
else
repeat on timeout, increase timeout on each failure
#+BEGIN_important
ARP Packet received
if IP address = our address
put the sender information into the ARP table
reply with our Ethernet address as target
else
if IP address in the table
update entry
else
do not update
Pourquoi la requête ARP est envoyée en broadcast?
Pour atteindre tous les hôtes/routeurs connectés au même réseau local.
Pourquoi la réponse ARP est envoyée en unicast ?
Pour atteindre seulement l'expéditeur de la requête ARP.
Pouvons-nous apprendre l'adresse MAC de n'importe quel hôte dans l'Internet en utilisant ARP ?
Non, nous ne pouvons connaître l'adresse MAC que d'un hôte/routeur connecté directement à notre réseau local.
Si un hôte a besoin d'envoyer un paquet à un routeur, a-t-il besoin de trouver aussi l'adresse MAC du routeur?
Oui, l'hôte obtient l'adresse IP du next-hop dans la table de routage et il a besoin de trouver son adresse MAC correspondant à l'aide de ARP.
1.2.5 IP Multicast
IP offre la possibilité d'envoyer un paquet en multicast : un paquet atteindra tous les hôtes inscrits à un groupe de multicast. Le multicast IP est utilisé pour la construction des tables de routage, dans le streaming, et pour d'autres types d'applications.
Les adresses de la Classe D (adresses de 224.0.0.0 à
239.255.255.255) permettent d'identifier des groupes
multicast. Quelques adresses sont réservées :
-
224.0.0.1 - tous les systèmes capables d'assurer le service multicast sur le sous-réseau,
-
224.0.0.2 - tous les routeurs multicast sur le sous-réseau.
IP utilise le paradigme du groupe ouvert : n'importe quel hôte peut envoyer un paquet à un groupe – pas besoin d'une autorisation spéciale pour l'envoi d'un paquet à un groupe. Un hôte source peut envoyer un paquet à un groupe peu importe s'il appartient au groupe ou non. Un hôte peut appartenir à plusieurs groupes différents.
Pour recevoir un paquet multicast, un hôte doit souscrire à une adresse de groupe à l'aide d'un protocole spécifique : IGMP (Internet Group Management Protocole).
Les routeurs construisent un arbre de distribution de multicast à tous les membres d'un groupe en utilisant un protocole de routage multicast tel que PIM (Protocol-Independent Multicast). Si nécessaire, les routeurs répliquent un paquet pour la livraison à tous les membres d'un groupe.
Pour atteindre tous les hôtes d'un groupe donné sur un réseau local Ethernet, un routeur encapsule un paquet IP multicast dans une trame qui a l'adresse de destination de groupe. Cette adresse est dérivée de l'adresse IP de l'adresse de groupe.
1.2.6 IPv6 (RFC 2460)
Cette partie fournit les détails du protocole IPv6.
1.2.6.1 Champs d'en-tête
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ |Version| Traffic Class | Flow Label | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Payload Length | Next Header | Hop Limit | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | | + + | | + Source Address + | | + + | | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | | + + | | + Destination Address + | | + + | | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
L'en-tête d'un paquet IPv6 a les champs suivants:
- Version Number
- quatre bits spécifiant la version IP.
- Traffic Class
- QoS sur les agrégats de trafic - le codepoint de DiffServ sur 1 octet.
- Flow Label
- identifie les paquets appartenant au même flot pour assurer la qualité de service de ce flot.
- Payload Length
- longueur en octets de la charge utile de paquets (données qui suivent l'en-tête).
- Next Header
- indique le type de l'en-tête suivant immédiatement l'en-tête de base.
- Hop Limit
- comme TTL - il est décrémenté chaque fois que le paquet est transmis par un routeur, le paquet est détruit s'il atteint zéro.
- Adresses source et destination
- adresses de 16 octets.
1.2.6.2 Extensions d'en-tête
Toute les informations que le paquet doit avoir et qui ne rentrent pas dans l'en-tête de base sont encapsulées dans des en-têtes d'extension.
- Hop by Hop
- doit être traitée par chaque nœud sur le chemin vers la destination.
- Destination
- l'information ne doit être traitée que par l'hôte de destination.
- Fragment
- similaire à IPv4, mais seule la source peut fragmenter les paquets. Les paquets dépassant la taille maximale sont rejetées par les routeurs et un message ICMP est envoyé à la source.
- Authentication
- support d'IPSec.
- Encapsulating security payload
- support d'IPSec.
1.2.6.3 Adresses IPv6
La taille des adresses IPv6 est de 16 octets (128 bits), 4 fois plus de bits qu'en IPv4 (nombre d'adresses: \(3,4 \times 10^{38}\)).
Notation:
- 8 groupes de 16 bits en hexadécimal, 4 chiffres hexadécimaux séparés par ":"
- les zéros en tête de chaque groupe peuvent être ignorés
- un groupe de zéros peut être remplacé par "::"
- la notation CIDR comme dans IPv4: préfixe/len
Exemples:
2001:660:5301:26:210:83ff:fe35:3404/64fe80::210:83ff:fe35:3404::1/128(loopback)2000::123:4567:89AB:CDEFFF05::1:3
Types et la portée des adresses :
- unicast comme dans IPv4,
- anycast : une adresse commune à plusieurs hôtes - un paquet est envoyé à l'hôte le "plus proche",
- multicast : préfixe FF00::/8 (il n'y a pas de broadcast en IPv6),
- les adresses IPv4 en IPv6 (IPv4-mapped IPv6 addresses) :
FFFF:<adresse IPv4>, par exemple :FFFF:129.144.52.38, - link-local : préfixe
FE80::/10, - adresses globales : accessibles sur l'Internet, le préfixe
2000::/3.
Qu'est ce qu'un paquet envoyé en anycast ?
Un paquet envoyé à l'hôte "le plus proche".
1.2.6.4 Adresses IPv6 multicast:
Format : préfixe sur 8 bits (11111111) + 4-bit flags + 4-bit scope + 112-bit group ID
- flags : bit T = 1 - adresse permanente
- scope est une valeur sur 4 bits qui définit la portée du groupe multicast :
1 Interface-Local scope 2 Link-Local scope 4 Admin-Local scope 5 Site-Local scope 8 Organization-Local scope E Global scope.
Exemples :
-
FF02::101 - all link-local NTP servers (scope = 2, NTP group = 101),
-
FF02:0:0:0:0:0:0:1 - all link-local nodes.
Solicited-node multicast address (Adresse multicast sollicitée) :
Ce type d'adresse est une adresse multicast générée en fonction d'une
adresse unicast ou anycast d'un nœud. Elle est créée en prenant 24
bits de poids faible d'une adresse (unicast ou anycast) en ajoutant
ces bits au préfixe FF02:0:0:0:0:1:FF00::/104 ce qui donne une
adresse multicast dans le plage de FF02:0:0:0:0:1:FF00:0000 à
FF02:0:0:0:0:1:FFFF:FFFF. Par exemple:
- l'adresse multicast Solicited-node correspondant à l'adresse IPv6
4037::01:800:200E:8C6CestFF02::1:FF0E:8C6C.
Qu'est-ce que l'adresse multicast Solicited-node ?
Elle est dérivée de l'adresse unicast ou anycast d'un nœud et utilisée pour la découverte de voisins.
1.2.7 ICMPv6
Remplace ICMP et ARP d'IPv4.
Principaux messages ICMPv6 :
- Destination unreachable (type 1) - Packet too big (type 2) - Time exceeded (type 3) - Parameter problem (type 4) - Echo request/reply (type 128 and 129)
Découverte de voisins (Neighbor Discovery) :
- Remplace ARP, ICMP (redirection, découverte de routeur)
1.2.7.1 Autoconfiguration sans état
IPv6 prend en charge la configuration automatique des adresses.
1.2.7.2 Les adresses link-local (lien-local)
Un nœud crée une adresse link-local par la concaténation du préfixe
link-local FE80::/10 et de l'identifiant d'interface sur 64 bits
appelé EUI-64 (Extended Unique Identifier).
EUI-64 est obtenu à partir de l'adresse MAC sur 48 bits : l'adresse MAC est d'abord séparée en deux parties de 24 bits. Le motif 0xFFFE sur 16 bits est ensuite inséré entre ces deux parties pour former l'identificateur EUI-64. Enfin, le septième bit de la gauche (le bit universal/local, U/L ), doit être inversée.
- Exemple d'EUI-64:
- adresse Ethernet sur 48 bits :
00:90:27:17:FC:0F - EUI-64 sur 64 bits, 7ème bit inversé :
02:90:27:FF:FE:17:FC:0F
- adresse Ethernet sur 48 bits :
- Exemple d'adresse link-local créée :
FE80::290:27FF:FE17:FC0F
1.2.7.3 Adresses globales routables
- Pour obtenir une adresse globale sur l'Internet, un nœud a besoin d'apprendre son préfixe à l'aide de messages de type Router Solicitation and Advertisement. On suppose qu'il existe un routeur reliée au même lien (réseau local) que le nœud en question.
- Au moment du démarrage, un nœud doit joindre 2 groupes spéciaux de
multicast pour chaque interface réseau :
- le groupe multicast de tous les nœuds :
ff02::1 - le groupe Solicited-Node multicast:
ff02::1:ffXX:XXXX, les bitsXX:XXXXproviennent des 24 bits de poids faible de l'adresse du nœud.
- le groupe multicast de tous les nœuds :
- Lorsque le nœud A a besoin d'apprendre le préfixe, il envoie :
ICMPv6 Type = 133 (Router Solicitation), Src = link-local address, Dst = all-routers multicast address (FF02::2), Query = Please send RA
- Le routeur répond avec un paquet ICMPv6 à tous les nœuds sur le lien :
ICMP Type = 134 (Router Advertisment), Src = link-local address, Dst = all-nodes multicast address (FF02::1), Data = options, subnet prefix, lifetime
Exemple: si le préfixe est 2001:660:5301::/48, l'adresse routable
est 2001:660:5301::290:27FF:FE17:FC0F.
1.2.7.4 Accessibilité des voisins
Neighbor Solicitation (ICMPv6 type 135) et Neighbor Advertisement (ICMPv6 type 136) remplacent ARP.
- Pour trouver l'adresse MAC du voisin B, hôte A envoie un paquet ICMPv6 :
ICMP Type = 135 (Neighbor Solicitation), Src = A, Dst = Solicited-Node multicast of B, Data = link-layer address of A, Query = what is your link address?
- B répond avec un paquet ICMPv6 :
ICMP Type = 136 (Neighbor Advertisement), Src = B, Dst = A, Data = link-layer address of B
1.2.7.5 Détection d'adresses dupliquées (DAD)
Quand un nœud crée son adresse link-local, il doit vérifier que l'adresse est unique en envoyant un paquet Neighbor Solicitation à l'adresse Solicited-Node multicast correspondant à son adresse link-local. En l'absence de réponse, on peut conclure que l'adresse est unique.
Exemple: si le nœud crée l'adresse link-local
FE80::290:27FF:FE17:FC0F, l'adresse multicast sollicitée multicast
correspondant est FF02::1:FE17:FC0F.
1.3 Protocoles de routage
Un protocole de routage permet de trouver les meilleures routes pour toutes les destinations, meilleur signifie que la route est la plus courte en terme d'une métrique donnée, par exemple le nombre de hops (passage par des routeurs) ou le délai. Le protocole construit des tables de routage qui reflètent l'information sur les meilleures routes : le routeur next-hop à utiliser pour la transmission d'un paquet vers une destination donnée.
1.3.1 Vecteur de distance
Dans le protocole à Vecteur de Distances (Distance Vector), les routeurs annoncent périodiquement leur vecteurs de distance: \(D(k, n)\), la distance du routeur \(k\) à la destination \(n\) (distance fonction d'une métrique). Les routeurs estiment la distance à chaque voisin - \(c(i, k)\). Lorsque le routeur \(i\) reçoit les vecteurs de distance de tous ses voisins, il choisit la meilleure route à destination de \(n\) de la manière suivante :
$$D(i, n) = \min_k(c(i, k) + D(k, n))$$
où \(c(i, k)\) est la distance estimée au voisin \(k\).
Le protocole à Vecteur de Distances souffre du problème du comptage à l'infini : les routeurs échangent leurs vecteurs en augmentant la distance. Il existe deux façons de résoudre ce problème :
- Horizon Partagé (Split Horizon)
- un routeur ne peut pas annoncer sa route à un voisin, si le voisin est le next-hop pour une destination donnée. (La version Reverse Poisoning : un routeur annonce ces routes avec une distance infinie).
- Distance Maximale
- on fixe une limite à la distance et si le comptage à l'infini atteint cette limite, on arrête.
Des exemples de protocoles de routage : RIP, IGRP.
Considérons un réseau composé de six routeurs \(R_i, i = 1, ..., 6\)
connectés en anneau. Le sous-réseau de préfixe 1.1.1/24 est
relié à \(R_1\) et le sous-réseau de préfixe 4.4.4/24 est reliée à
\(R_4\). Nous négligeons tous les autres préfixes. Tous les routeurs
exécutent un protocole de routage à vecteur de distances tel que
RIP avec Split Horizon. Sauf indication contraire, le coût d'un
lien entre deux routeurs est égal à 1. Le coût d'un routeur vers
un réseau directement connecté est 0.
- Donner les annonces de \(R_2\), \(R_3\), \(R_5\), et \(R_6\).
- Après la propagation des annonces dans le réseau, donner les tables de routage de \(R_1\) et \(R_4\) sous la forme : Destination Network, Next-Hop, Distance.
- Les liens entre \(R_2\) et \(R_3\), \(R_5\) et \(R_6\) tombent. Donner les nouvelles tables de routage.
\(R_2\) : 1.1.1/24, \(d=1\);4.4.4/24, \(d=2\)\(R_3\) : 1.1.1/24, \(d=2\);4.4.4/24, \(d=1\)\(R_5\) : 1.1.1/24, \(d=2\);4.4.4/24, \(d=1\)\(R_6\) : 1.1.1/24, \(d=1\);4.4.4/24, \(d=2\)- \(R_1\) :
Destination Network Next-Hop Distance 1.1.1/24direct 0 4.4.4/24\(R_2\) 3 \(R_4\) :
Destination Network Next-Hop Distance 1.1.1/24\(R_5\) 3 4.4.4/24direct 0 - \(R_6\) peut recevoir l'annonce de \(R_1\) :
4.4.4/24, avec la distance \(d=3\) que \(R_1\) peut aussi annoncer même s'il applique Split Horizon (\(R_1\) relaie vers la destination4.4.4/24via \(R_2\), donc il peut annoncer cette route à \(R_6\)). \(R_6\) accepte cette route. Toutefois, lorsque \(R_2\) annonce la route4.4.4/24avec \(d=\infty\), \(R_1\) va transférer cette route à \(R_6\), et, enfin, toutes les tables de routage correspondent à la nouvelle topologie - le préfixe4.4.4/24est inaccessible.
1.3.2 États de liens (Link State)
Dans les protocoles à états de liens, les routeurs annoncent des informations sur leurs liens (distance, voisin) à tous les routeurs du réseau. Les routeurs utilisent le principe d'inondation (flooding) : un routeur reçoit un message de routage sur un lien et le transmet sur tous ses liens sortants. De cette façon, tous les routeurs reçoivent les messages de tous les routeurs et peuvent construire le graphe du réseau - ils découvrent la topologie détaillée du réseau.
Pour trouver les meilleurs routes à toutes les destinations, un routeur exécute un algorithme d'optimisation de graphe tel que l'algorithme de Dijkstra pour trouver le chemin le plus court dans un graphe.
1.3.2.1 Algorithme de Dijkstra exécuté sur le routeur A
- Initialisation: Variable
PATH: routeur A (les meilleurs chemins vers des destinations) variableTENT: vide (chemins provisoires) - Pour chaque routeur \(N\) dans
PATHpour chaque voisin \(M\) de \(N\)$$c(A, M) = c(A, N) + c(N, M)$$
si \(M\) n'est pas dans
PATH, ni dansTENTavec un meilleur coût, insérez \(M\) avec \(N\) dansTENT - Si
TENTest vide, fin. Sinon, prendre l'entrée avec le meilleur coût dansTENT, insérez-la dansPATHet aller à 2.
À la fin, PATH contient l'arbre des meilleurs chemins vers toutes
les destinations : les next-hop et la distance la plus courte pour
toutes les destinations.
1.3.3 Routage externe - BGP (Border Gateway Protocol)
L'Internet est une interconnexion de systèmes autonomes (Autonomous Systems - AS) : un ensemble d'hôtes et de routeurs regroupés sous une seule autorité qui présente une politique de routage commune vis-à-vis des autres AS. Chaque AS gère un des protocoles de routage interne pour le transfert de paquets vers et à partir de ses sous-réseaux (RIP, OSPF, IGRP). Un AS annonce ses préfixes à d'autres ASs avec un protocole de routage externe tel que BGP (Border Gateway Protocol). Un AS apprend tous les autres préfixes en utilisant BGP.
Un routeur BGP d'un AS reçoit de l'information sur les préfixes et leurs attributs des autres AS et annonce les préfixes de ses sous-réseaux. Un attribut commun est AS_PATH : l'ensemble des AS à traverser pour atteindre une destination annoncée. Un routeur BGP prend des décisions de routage basées sur l'attribut AS_PATH, des politiques de routage ou des règles configurées par un administrateur réseau.
2 Couche liaison et les réseaux locaux

La couche liaison organise la communication entre deux périphériques directement connectés par une couche physique (support de communication) qui permet la transmission d'information binaire.
Elle structure l'information binaire en trames en ajoutant habituellement des délimiteurs de trames, de l'information de contrôle et des bits de redondance pour la détection d'erreur (CRC). Exemples : le protocole PPP (Point-to-Point Protocol).
La couche liaison inclue également les réseaux locaux (LAN - Local Area Networks), même si le terme réseau peut paraître contradictoire par rapport à la définition de la couche liaison. Dans un réseau local, plusieurs dispositifs utilisent un support de transmission commun (médium de transmission).
Le principal problème posé par les réseaux locaux et sa couche d'accès au médium (Medium Access Control) est de contrôler l'accès de plusieurs dispositifs en compétition pour éffectuer une transmission sur le médium partagé (câble partagé, canal radio, etc.). Différents réseaux locaux utilisent des protocoles MAC spécifiques : Ethernet utilise CSMA/CD, 802.11 (Wi-Fi) utilise CSMA/CA (à voir plus bas).

2.1 PPP (Point-to-Point Protocol)
PPP fournit un moyen de transmission de paquets sur des liaisons point à point. Il définit un format de trame hérité des premiers réseaux de commutation de paquets (HDLC).
+----------+----------+----------+ | Flag | Address | Control | | 01111110 | 11111111 | 00000011 | +----------+----------+----------+ +----------+-------------+---------+ | Protocol | Information | Padding | | 8/16 bits| * | * | +----------+-------------+---------+ +----------+----------+----------------- | FCS | Flag | Inter-frame Fill |16/32 bits| 01111110 | or next Address +----------+----------+-----------------
La trame PPP est délimitée par la séquence Flag 01111110
(hexadécimal 0x7e). FCS (Frame Check Sequence) est calculé en
utilisant un code polynomial de détection d'erreurs pour identifier
les trames corrompues.
Le protocole PPP implémente également un mécanisme de transparence (la
possibilité d'envoyer toute valeur d'octet dans le champs Information)
à travers l'opération de Byte Stuffing. On définit un octet
d'échappement (Control Escape) comme le code binaire 01111101
(hexadécimal 0x7d), le bit le plus significatif en premier.
2.1.1 Byte stuffing
Chaque octet que ce soit Flag Sequence, Control Escape ou toute valeur d'octet de moins de 0x20 est remplacé par une séquence de deux octets constituée par l'octet Control Escape suivi par un octet résultat d'un "ou-exclusif" (exclusive-or) entre l'octet d'origine et la valeur hexadécimale 0x20 .
Exemples :
0x7eest codé0x7d 0x5e(Flag Sequence),0x7dest codé0x7d 0x5d(Control Escape),0x03est codé0x7d 0x23(caractère ETX).
À la réception, chaque octet Control Escape est retiré et on fait un
ou-exclusif (exclusive-or) entre l'octet suivant et la valeur
hexadécimale 0x20, sauf si l'octet suivant est Flag Sequence (ce
qui termine la réception de la trame).
L'émetteur fournit la séquence suivante au protocole PPP.
0x7e, 0x41, 0x7d, 0x33, 0x01
Quelle est la séquence observée sur le canal de communication ?
0x7d, 0x5e, 0x41, 0x7d, 0x5d, 0x33, 0x7d, 0x21
Le recepteur reçoit la séquence suivante :
0x7d, 0x5e, 0x41, 0x7d, 0x5d, 0x33, 0x7d, 0x21
Quelle est la séquence reçue par le protocole au-dessus de PPP ?
0x7e, 0x41, 0x7d, 0x33, 0x01
2.2 Ethernet
Ethernet est un réseau local câblé qui a évolué au fil du temps de la variante initiale de 10 Mb/s sur un câble coaxial aux technologies récentes 10 Gb/s voire 100 Gb/s sur fibre. Le principe de son fonctionnement est basé sur un accès aléatoire qui permet d'obtenir de très bonnes performances pour une intensité faible de trafic.
2.2.1 Variante initiale
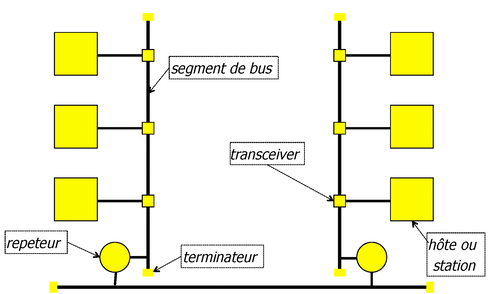
La topologie est sous forme de segments de bus (câble coaxial) : un segment (épine dorsale) relie tous les autres segments. Le câble fournit le support de transmission commun avec un débit nominal de 10 Mb/s qui permet la transmission en broadcast (diffusion) : une trame envoyée par une station se propage sur le câble pour atteindre tous les autres appareils connectés, ce qui signifie que toutes les stations reçoivent toutes les trames transmises. Une trame envoyée à destination d'une seule station est reçue par toutes les stations et seule la station qui reconnait son adresse de destination, reçoit la trame.
Pour étendre la couverture spatiale du réseau, les répéteurs entre les segments amplifient le signal et retransmettent la trame envoyée sur un autre segment. Il y a des limites à la longueur du segment, le nombre de répéteurs, et la topologie du réseau qui impose une limite au temps d'aller-retour entre deux stations connecté au réseau à \(51,2 \mu s\) : la station qui envoie une trame est sûre qu'au bout de cet intervalle de temps, le début de sa trame a été reçu par toutes les stations dans le réseau.
2.2.2 Méthode d'accès CSMA/CD
n = 0 REPETER attendre que le canal soit libre attendre un temps intertrame (interframe gap) transmettre et détecter la collision SI (collision détectée) ALORS arrêter la transmission transmettre jam (32 bits) n ++ SI (n == maxAttempts) ALORS abandon FIN_SI k = min (n, 10) r = random (2^k - 1) attendre temps aléatoire (r × SLOTTIME) SINON transmission réussie FIN_SI JUSQU'A (transmission réussie ou abandon)
Une station qui veut transmettre, teste si le canal est déjà utilisé (carrier sense). Si le canal est libre, la station attend un intervalle appelé interframe gap (\(9,6\mu s\)) et transmet la trame. Lors de la transmission, elle vérifie si une collision se produit (en détectant une puissance accrue du signal sur le câble en raison d'un chevauchement de transmissions). En cas de collision (collision detected), la station cesse d'émettre la trame et transmet une séquence de bits aléatoires appelée jam (32 bits). Puis, elle incrémente \(n\), le compteur de collisions et choisit un intervalle de retransmission aléatoire :
$$T = r \times \mbox{SLOTTIME}$$
où
- \(r = \mbox{random}(2^k - 1)\),
- \(k = \min(n, 10)\),
- \(\mbox{SLOTTIME} = 51.2 \mu s\).
L'intervalle des valeurs de \(r\) pour les collisions successives est le suivant :
- Première collision, \(r \in [0, 1]\)
- Deuxième collision, \(r \in [0, 3]\)
- 10, \(r \in [0, 1023]\)
- …
- 14, \(r \in [0, 1023]\)
- 15, on arrete.
Une autre collision peut se produire si les deux stations choisissent la même valeur de \(r\) ce qui arrive avec une probabilité \(1/2\) pour la première collision, \(1/4\) pour la seconde, puis \(1/2^k\).
L'augmentation de l'intervalle pour choisir \(r\) de manière exponentielle est appelé exponential backoff.
La station retransmet la trame impliquée dans une collision après l'intervalle de retransmission (elle suit toujours la règle principale d'accès au canal : attendre que l'activité cesse sur le canal et attendre l'interframe gap).
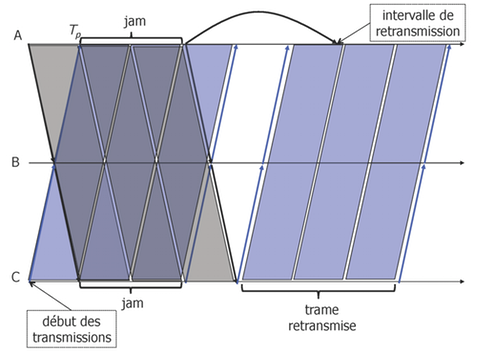
La figure 10 illustre comment une collision est récupérée :
- à l'instant \(t = 0\), deux stations \(A\) et \(C\) ont des trames à envoyer, ils testent le canal et commencent à envoyer leurs trames, car le canal est libre à cet instant
- à l'instant \(t = T_p\), lorsque le signal de \(A\) arrive à \(C\) (et le signal de \(C\) à \(A\)), les deux stations détectent une collision, arrêtent leur transmissions et envoyent une séquence de bourrage
- après la séquence de bourrage, ils choisissent des intervalles de
retransmission aléatoires :
- \(A\) choisit un SLOTTIME, il reporte alors la tentative de transmission
- \(C\) choisit 0, il peut alors procéder
- \(C\) teste le canal (il y a encore le signal correspondant à la séquence de bourrage de \(A\)), attend la fin du signal et envoie sa trame
- lorsque \(A\) teste le canal après un SLOTTIME, il y a encore la transmission de \(C\) en cours, il attend alors la fin de la trame
- \(A\) transmet après la fin de la trame de \(C\) (non représenté sur la figure).
Le SLOTTIME de \(51,2\mu s\) garantit qu'après le début d'une transmission, toutes les stations reçoivent le signal émis (canal occupé) ce qui fait que les stations ne vont pas initier une nouvelle transmission (les collisions ne peuvent pas se produire après cet intervalle). La valeur de \(51,2 \mu s\) vient de la limitation de la longueur d'un segment et du nombre maximal de répéteurs entre deux stations : tous les délais de propagation seront inférieurs à \(51,2 \mu s\), la valeur qui correspond à la transmission de 64 octets sur un débit nominal de 10 Mb/s. Cette limitation entraîne les propriétés suivantes :
- \(51,2 \mu s\) est l'unité de retransmission : si après une collision, une station tente de retransmettre après \(51,2 \mu s\), soit le canal est libre et la station essaie de transmettre, soit il y a une transmission en cours et la station va attendre sa fin (nous évitons d'autres collisions),
- Si une station a déjà envoyé 64 octets, le canal est acquis par la station - il n'y aura pas de collisions au cours de la transmission,
- Si il y a une collision, le reste de la transmission d'une trame (trame coupée) aura une taille \(< 64\) octets. Toute trame avec une taille $<64$octets est considérée comme invalide.
Trois stations A, B, C sont connectés par un Ethernet 10 Mb/s. Ils sont placées à une distance de : AB 1 km, BC 1 km, AC 2 km. A \(t=0\), stations A et C ont une trame de taille minimale à envoyer et il y a en cours une transmission par B qui se termine à \(t=5 \mu s\). On suppose que s'il y a une collision, les deux stations choisissent un nombre différent de slots. Donnez la chronologie de ce qui se passe (les instants et les événements).
| \(t=0\), | le début |
| \(t=5 \mu s\), | fin de la transmission de B |
| \(t=10 \mu s\), | A détecte le canal libre |
| \(t=10 \mu s\), | C détecte le canal libre |
| \(t=19,6 \mu s\), | A commence la transmission après le gap |
| \(t=19,6 \mu s\), | C commence la transmission après le gap |
| \(t=29,6 \mu s\), | le signal de A arrive à C, détection de la collision |
| \(t=29,6 \mu s\), | le signal de C arrive à A, détection de la collision |
| \(t=32,8 \mu s\), | fin de jam par A, A choisit \(r=0\) |
| \(t=32,8 \mu s\), | fin de jam par C, C choisit \(r=1\), attente jusqu'à \(t=84 \mu s\) |
| \(t=42,8 \mu s\), | dernier bit de jam arrive à A |
| \(t=42,8 \mu s\), | dernier bit de jam arrive à C |
| \(t=52,4 \mu s\), | A commence la transmission après le gap |
| \(t=84,9 \mu s\), | C détecte le canal occupé |
| \(t=103,6 \mu s\), | fin de la transmission de A |
| \(t=113,6 \mu s\), | dernier bit de la transmission de A arrive à C |
| \(t=123,2 \mu s\), | C commence la transmission après le gap |
| \(t=174,4 \mu s\), | fin de la transmission de C |
| \(t=184,4 \mu s\), | dernier bit de la transmission de C arrive à A |
2.2.3 Format de trame, les adresses
Encapsulation Ethernet 2 :
0 1 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | DST_ADDR | | (6 octets) | | | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | SRC_ADDR | | (6 octets) | | | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | ETHER_TYPE (2 octets) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ ~ ~ ~ payload ~ ~ (46 - 1500 octets) ~ +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | CHECKSUM (4 octets) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Le champ DST_ADDR contient soit une adresse unicast ou une adresse
de groupe (dans ce cas là, le premier bit de l'adresse = 1). Les
données sur Ethernet sont transmises dans l'ordre suivant : le bit le
moins significatif du premier octet en premier (un bug de processeurs
Intel). La représentation canonique ainsi inverse l'ordre des bits
dans un octet (le premier bit de l'adresse est le bit le moins
significatif du premier octet).
Les adresses sont représentées selon notation hexadécimale suivante :
08:00:20:71:0d:d4. L'adresse de diffusion est ff:ff:ff:ff:ff:ff
(broadcast).
Exemples :
- une adresse de groupe :
01:00:5e:02:a6:cf. - une adresse multicast pour IPv4 :
01:00:5e:02:a6:cf. - une adresse de multidiffusion pour IPv6 :
33:33:ff:02:a6:cf.
ETHER_TYPE détermine le protocole de la couche supérieure à laquelle
la charge utile doit être remise: 0x0800 (IPv4), 0x86DD (IPv6),
0x0806 (ARP).
Pourquoi la trame Ethernet a-t-elle une taille minimale?
La trame doit être plus longue que 64B ce qui correspond à \(51,2 \mu s\) nécessaires pour la propagation du signal dans tout le réseau.
2.2.4 Evolution d'Ethernet
Fast Ethernet : 100 Mb/s sur 4 paires torsadées.
Gigabit Ethernet : 1 Gb/ s, 10 Gb/s, 40 Gb/s sur fibre.
Le câblage avancé par rapport à la version initiale utilise des câbles de paires torsadées et une interconnexion des stations avec des hubs (répéteurs multiports ou un concentrateur). Un hub est un élément d'interconnexion au niveau de la couche physique : il reçoit un signal et le retransmet sur tous les ports sortants.
Switches (commutateurs) interconnectent des stations en relayant des trames sur la base des adresses MAC de destination. Un switch est un élément d'interconnexion de niveau de la couche 2 (liaison) : il reçoit une trame, vérifie sa validité (CRC, taille) et retransmet sur le port sortant vers la station de destination (mode de fonctionnement Store and Forward).
Un pont fonctionne de manière similaire, mais il peut interconnecter des réseaux locaux hétérogènes, par exemple, un point d'accès 802.11, c'est un pont entre l'Ethernet filaire et le réseau sans fil 802.11 (Wi-Fi) connectant des stations mobiles.
Ethernet full-duplex : il permet d'envoyer et de recevoir en même temps. Aucune collision possible.
Deux stations A, B sont reliées par un Ethernet 10 Mb/s à travers un hub H. Ces éléments sont placés à une distance de : AH 1km, HB 1 km, AB 2 km. À \(t=0\), station A a une trame de taille minimale à envoyer. Donnez l'enchainement temporel de ce qui se passe (les instants et les événements).
| \(T=0\), | début |
| \(T=9,6 \mu s\), | A commence la transmission après l'interframe gap |
| \(T=14,6 \mu s\), | H reçoit le signal et retransmet à B |
| \(T=19,6 \mu s\), | B reçoit le signal |
| \(T=70,8 \mu s\), | B reçoit la trame |
Deux stations A, B sont connectés par un Ethernet 10 Mb/s à travers un switch S. Ces éléments sont placés à une distance de : AS 1km, SB 1 km, AB 2 km. À \(t=0\), station A a une trame de taille minimale à envoyer. Donnez l'enchainement temporel de ce qui se passe (les instants et les événements).
| $T=0 $, | début |
| \(T=9,6 \mu s\), | A commence la transmission après l'interframe gap |
| \(T=14,6 \mu s\), | S reçoit le signal |
| \(T=65,8 \mu s\), | S reçoit la trame et retransmet à B |
| \(T=70,8 \mu s\), | B reçoit le signal |
| \(T=122,0 \mu s\), | B reçoit la trame |
2.2.5 Switches apprenant (ou ponts apprenant)
Le fonctionnement des switches (ou ponts) repose sur des tables de relayage qui fournissent de l'information sur le port sortant pour une destination donnée identifiée par l'adresse MAC.
Les switches (ou ponts) sont des dispositifs plug-and-play: leurs tables de relayage sont vides au départ et ils apprennent l'emplacement des stations (le couple adresse MAC - port sortant) à partir des adresses source des trames émises par des stations.
Quand une adresse de destination n'est pas encore dans la table de relayage, les switches utilisent l'inondation : ils répliquent la trame et la relayent sur tous les ports sortants.
L'inondation résout le problème d'initialisation de la table de relayage, mais cette technique souffre du problème d'augmentation du nombre de trames en transit si la topologie d'interconnexion des switches (ou ponts) interconnexion contient une boucle.
Deux stations A, B sont connectés par un Ethernet 10 Mb/s à travers un switch S. Ces éléments sont placés à une distance de : AS 1km, SB 1 km, AB 2 km. À \(t=0\), station A a une trame de taille minimale à envoyer. Donnez la table de relayage de S après la réception de la trame de A.
| adresse MAC | port sortant |
|---|---|
| adresse de A | port connecté à A |
2.3 802.11 (Wi-Fi)
La norme IEEE 802.11 définit des réseaux locaux sans fil qui fournissent la connectivité à des stations mobiles. 802.11 utilise deux bandes de fréquences sans licence :
- 802.11b/g/n : de 2,4 à 2,483 GHz (plusieurs canaux de 22 MHz de largeur)
- 802.11a : de 5,15 à 5,725 GHz (plusieurs canaux de 22 MHz de largeur)
Le débit nominal est de 11 Mb/s pour la norme 802.11b, 54 Mb/s pour la norme 802.11g et 72 Mb/s pour la norme 802.11n (sur un seul canal de 22 MHz).
Lorsque les conditions de transmission sont mauvaises, une station peut réduire son débit en utilisant une modulation plus robuste, par exemple, réduire de 11 Mb/s à 5,5, 2 ou 1 Mb/s.
802.11 utilise la méthode d'accès CSMA/CA, similaire à CSMA/CD d' Ethernet, mais avec deux différences majeures :
- Pas de possibilité de détecter une collision lors d'une transmission,
- Un canal radio a un taux d'erreur plus élevé par rapport aux câbles. Les stations utilisent des acquittements pour améliorer la fiabilité du lien radio.
802.11 couvre une distance de l'ordre de ~50 m à l'intérieur.
Les stations considèrent une carte d'interface réseau 802.11 comme une interface Ethernet - l'interface 802.11 présente la même limitation de la taille de trames qu'Ethernet : la taille maximale des données est de 1500 octets.
2.3.1 CSMA/CA
Cas simple - faible charge, aucune activité sur le canal :
tester le canal
SI libre ALORS
attendre intervalle DIFS (long),
SI le canal libre ALORS
transmettre la trame
attendre intervalle SIFS (court)
recevoir ACK
FIN_SI
FIN_SI
Le cas plus complexe de la contention entre deux stations - il y a de l'activité sur le canal, stations appliquent l'évitement de collision : avant une transmission, elles choisissent un intervalle d'attente aléatoire :
Temps-résiduel = 0
n = 0
Début:
SI le canal est utilisé ALORS
attendre que le canal devienne libre,
attendre un intervalle DIFS (long)
SI le canal libre ALORS
SI Temps-résiduel > 0
attendre Temps-résiduel
SINON
choisir temporisation r dans la fenetre de contention [0, Wmax]
attendre r slots
SI on reçoit un signal de transmission ALORS
on arrête d'attendre, Temps-résiduel = slots restants, go to Début:
SINON
transmettre la trame
attendre intervalle SIFS (court)
attendre ACK
SI pas de ACK ALORS
Wmax <- 2*Wmax; n++; go to Début:
FIN_SI
FIN_SI
FIN_SI
FIN_SI
FIN_SI
La méthode d'accès CSMA/CA et le surcoût de l'en-tête font que le débit utile est assez faible par rapport au débit nominal : il est égal à environ 60% de 11Mb/s pour 802.11b - 6.5Mb/s mesuré au niveau de la couche application.
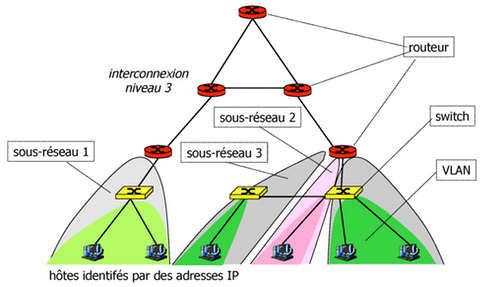
2.4 VLAN (Virtual LANs)
Les switch (commutateurs) VLAN (Virtual LANs) offrent la possibilité de créer plusieurs réseaux locaux logiques (réseaux locaux virtuels) sur une seule infrastructure physique. Par exemple, nous pouvons définir des VLAN distincts pour l'administration et pour étudiants pour des raisons de sécurité - il n'y a pas possibilité de transmission de trames entre différents VLAN (pas de communication possible au niveau de la couche liaison).
VLAN = ensemble des stations qui peuvent communiquer entre elles au niveau de la couche liaison.
Un switch VLAN associe une trame à un VLAN donné sur la base de :
- un étiquetage explicite (explicit tagging)
- - une étiquette de VLAN est insérée dans la trame de sorte qu'un commutateur peut décider à quels ports (donc, à quelle station il doit envoyer la trame). Exemple : trame définie dans la norme IEEE 802.1Q avec le champ de 12 bits pour une étiquette (tag) VLAN.
- informations implicites
- l'identificateur de VLAN est implicitement déduit : du numéro de port, de l'adresse MAC, ou de l'adresse niveau réseau (adresse IP).
Pour vérifier quelles stations appartiennent à un VLAN, on peut considérer la trame envoyée en broadcast - elle est reçue par toutes les stations appartenant au même VLAN.
2.4.1 VLAN par port
Cette technique permet de définir un VLAN à partir des ports de raccordement sur le commutateur. Toutes les machines reliées à ce port appartiendront au VLAN affecté à ce port. L'administrateur du switch configure cette association port/VLAN via la table des VLAN.
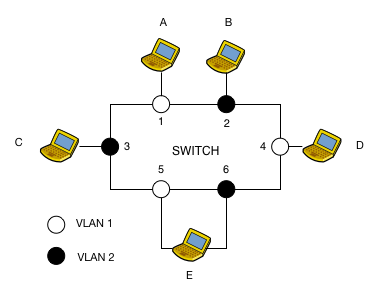
La table des VLAN du switch présenté en figure 11 est la suivante :
+-+-+-+-+-+-+-+-+-+-+ | TABLE VLAN | +-+-+-+-+-+-+-+-+-+-+ | Port | VLAN | +-+-+-+-+-+-+-+-+-+-+ | 1 | 1 | | 2 | 2 | | 3 | 2 | | 4 | 1 | | 5 | 1 | | 6 | 2 | +-+-+-+-+-+-+-+-+-+-+
Ainsi, une trame envoyée en broadcast par la machine A derrière le port 1 sera reproduite par le switch sur tous les ports appartenant au même VLAN que le port 1 à l'exclusion du port de réception (port 4 et 5).
La principale limite de VLAN de niveau 1 est qu'un port ne peut appartenir à plusieurs VLAN. Ainsi la machine E doit avoir 2 interfaces connectées à 2 ports différents pour appartenir à 2 VLAN différents.
2.4.2 VLAN 802.1Q
Afin de pallier cette limite et permettre à un port de relayer du trafic en provenance et à destination de différents VLAN, nous allons nous appuyer sur la norme 802.1Q qui permet de taguer les trames.
La figure suivante montre une trame Ethernet portant un tag 802.1Q.
0 1 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | DST_ADDR | | (6 octets) | | | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | SRC_ADDR | | (6 octets) | | | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ |ETHER_TYPE = 0x8100(<--802.1Q) | \ +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ \ | Priority (3 bits) | | --> 4 octets supplémentaires | CFI (1 bit) | / | VLAN ID (12 bits) | / +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | ETHER_TYPE (2 octets) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ ~ ~ ~ payload ~ ~ (46 - 1500 octets) ~ +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | CHECKSUM (4 octets) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Ce marquage peut se faire au niveau de l'interface des machines ou des ports des switches.
Coté switch, les ports doivent être configurés à travers la table des VLAN pour accepter/émettre du trafic tagué des VLAN autorisés sur ce port. Si du trafic non tagué arrive sur le port, il appartient au VLAN indiqué dans la table des VLAN.
La table des VLAN du switch présenté en figure 12 est la suivante :
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | TABLE VLAN | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Port | (un)tagged | VLAN | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | 1 | untagged | 1 | | 2 | untagged | 2 | | 2 | tagged | 1 | | 3 | untagged | 2 | | 4 | untagged | 1 | | 5 | tagged | 2 | | 5 | untagged | 1 | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
La table se lit de la manière suivante :
- le port 2 émet et accepte du trafic tagué du VLAN 1.
- le trafic non tagué entrant/sortant du port 2 appartient au VLAN 2
Ainsi une trame non taguée de broadcast émise par la machine D connectée derrière le port 4 sera reproduite sur les tous les ports appartenant au VLAN 1 avec un tag (VLAN 1) sur le port 2 et sans tag sur le port 1 et 5.
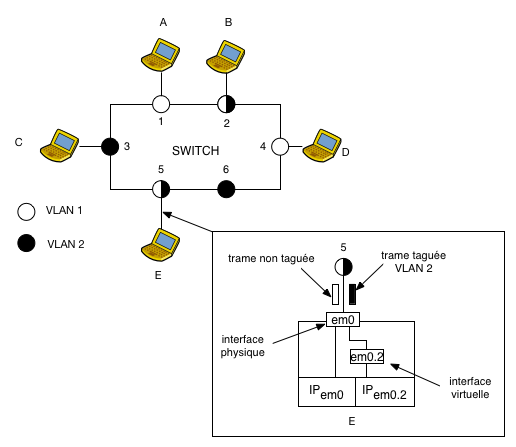
Coté machine, nous allons définir une nouvelle notion, celle d'interface virtuelle. À une même interface physique, on peut associer plusieurs interfaces virtuelles qui appartiendront à des VLANs différents.
Chaque interface virtuelle servira à fabriquer et recevoir des trames marquées. En créant ces interfaces, on spécifiera leur nom, leur tag, ou numéro de VLAN, ainsi que l'interface matérielle sur laquelle circulera le trafic.
Ces interfaces se configurent comme des interfaces Ethernet classiques. Ainsi tous les trames empruntant une interface virtuelle se verront automatiquement taguées du VLAN associé à cette interface.
Ansi au niveau de la machine E dispose de 2 interfaces : une interface physique em0 pour traiter les trames non taguées et une interface virtuelle em0.2 pour les trames taguées (VLAN 2).
Quand l'interface em0 reçoit une trame taguée, elle détermine le VLAN d'appartenance, retire le tag et aiguille la trame vers l'interface virtuelle liée à ce VLAN.
3 Couche transport
3.1 Transport
La couche de transport permet le transfert de données entre deux processus sur deux hôtes interconnectés à travers la couche réseau.
Les adresses de niveau transport sont les ports - ils servent à identifier les processus qui échangent des données.
Le besoin d'une couche de transport vient du fait que le protocole IP n'offre pas de qualité de communication parfaite : les paquets peuvent être perdus, ils peuvent arriver en désordre, ils peuvent contenir des données corrompues.
L'objectif de la couche de transport est de réaliser le transfert de données avec la qualité de service nécessaire, par exemple une fiabilité suffisante et l'ordre garanti.
3.1.1 Transfert de données fiable
Il existe plusieurs techniques pour garantir un transfert de données fiable.
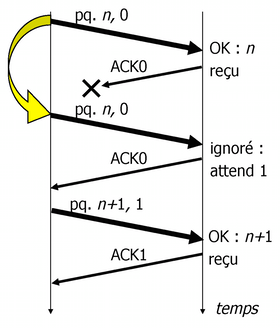
- Envoyer et attendre (Send and Wait)
- L'émetteur envoie un
segment de données et attend un accusé de réception (
ACK- Accusé de réception - la confirmation d'une bonne réception du segment) avant d'envoyer un nouveau segment de données. Nécessite tampon d'émission d'1 segment et tampon de réception d'1 segment. Faible performance pour un grand produit bande passante-délai.
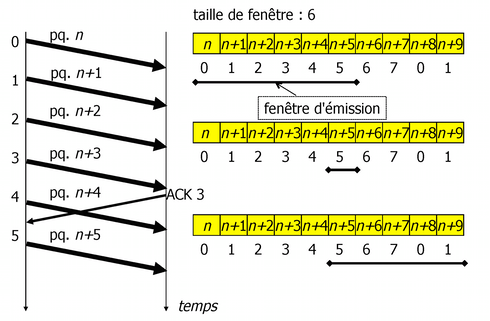
- Fenêtre glissante (Sliding Window)
- Pour améliorer les performances, l'expéditeur a la possibilité d'envoyer plusieurs segments (une fenêtre) sans attendre les accusés de réception. Ainsi, l'émetteur peut constamment émettre, si la fenêtre est suffisamment grande.
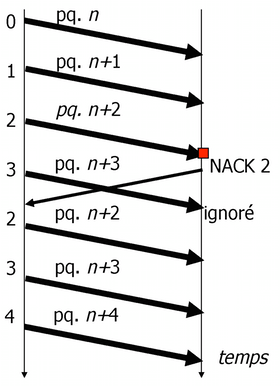
- Retransmission continue (Go-back-N)
- Dans le cas d'un segment perdu, l'expéditeur retransmet tous les segments à partir du segment manquant. Nécessite un tampon d'émission de taille \(W\) (\(W\) - la taille de la fenêtre) et un tampon de réception d'1 segment. Peut entraîner un manque de performance en raison de segments retransmis inutilement.
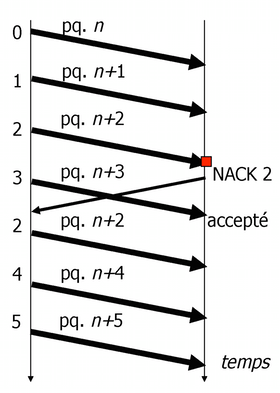
- Retransmission sélective (Selective Retransmit)
- Dans le cas d'un segment perdu, l'expéditeur retransmet uniquement le segment manquant. Nécessite un tampon d'émission et de réception de taille \(W\). Obtient la meilleure performance, mais le protocole est plus complexe à implémenter.
3.1.2 Contrôle de flux
Les segments de données stockés dans le tampon de réception peuvent être écrasées si le processus d'application ne lit pas les données suffisamment rapidement. L'objectif du contrôle de flux est d'informer et d'éventuellement bloquer l'émission de l'expéditeur pour éviter la perte de données.
Contrôle de flux à base de crédit. Le récepteur annonce la taille de la fenêtre à utiliser à l'expéditeur, sa valeur correspond à l'état actuel à la place libre dans son tampon de réception. La fenêtre annoncée de 0 signifie qu'il n'y a pas de place dans le tampon, donc l'expéditeur ne peut plus envoyer de données.
3.2 TCP (Transmission Control Protocol)
TCP (Transmission Control Protocol) offre un transfert fiable d'un
flot d'octets avec un contrôle de flux à base de crédit. La fiabilité
repose sur un mécanisme à base de la fenêtre glissante, la détection
des pertes par l'expéditeur sur le dépassement d'une temporisation, la
retransmission continue des segments perdus. L'optimisation appelée
"Fast Retransmit" (retransmission rapide) a comme effet le
fonctionnement similaire à la retransmission sélective avec la
détection de pertes isolées par l'expéditeur : 3 ACK dupliqués
indiquent un segment perdu qu'il faut retransmettre.
3.2.1 Segment TCP
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Source Port | Destination Port | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Sequence Number | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Acknowledgment Number | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Data | |U|A|P|R|S|F| | | Offset| Reserved |R|C|S|S|Y|I| Window | | | |G|K|H|T|N|N| | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Checksum | Urgent Pointer | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Options | Padding | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | data | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
L'en-tête d'un segment TCP comporte les champs suivants :
- Ports Source et Destination
- Les nombres sur 16 bits pour identifier le processus source et le processus de destination.
- Numéro de séquence
- sur 32 bits, le numéro du premier octet de données dans le segment.
- Numéro d'acquittement
- sur 32 bits, si le drapeau
ACKest positionné, le champACKindique le numéro de l'octet attendu dans le prochain segment. Ceci confirme la bonne réception de tous les octets avec les numérosACKinférieurs. - Data offset
- la taille de l'en-tête en mots de 32 bits. L'en-tête peut avoir des champs facultatifs, alors nous avons besoin de l'information sur sa taille.
- Drapeaux (Flags)
-
URG - pointeur urgent valide
-
ACK - numéro d'acquittement valide
-
PSH - force TCP à faire partir les données mises en tampon d'émmission
-
RST - réinitialise la connexion en cas d'anomalies
-
SYN - initialise une connexion en synchronisant les numéros de séquence
-
FIN - fin d'envoi de données
-
- Fenêtre Annoncée (Window)
- le nombre d'octets que le récepteur peut accepter.
- Checksum
- le complément à 1 sur 16 bits de la somme de tous les mots de 16 bits du segment TCP avec le pseudo-en-tête ajouté au début. Ce pseudo-en-tête contient l'adresse IP source, l'adresse IP de destination, le protocole, et la longueur du segment TCP.
- Pointeur Urgent (Urgent Pointer)
- un offset à partir du numéro de séquence qui pointe vers le octet suivant les données urgentes.
- Options
- MSS (Maximum Segment Size)
- la taille de segment proposé
pour la connexion (uniquement dans le segment
SYN). Le MSS choisi est le minimum des propositions de l'émetteur et de récepteur.
Qu'est-ce que c'est que le MSS ?
La plus grande quantité de données que les dispositifs de communication peuvent recevoir dans un segment TCP unique est mesurée par la taille maximale d'un segment (MSS) en octets.
3.2.2 Établissement de connexion et la terminaison
Un client et un serveur établissent une connexion après avoir échangé 3 segments (three-way handshake) :
- un segment
SYN(seulement l'en-tête TCP avec le drapeauSYNpositionné et le champSEQ) : le client propose son numéro séquenceSEQ\(= x\), - un segment
SYNACK: le serveur confirme avecACK\(= x + 1\) le numéro de séquence proposé (il attend octet \(x + 1\)) et il propose son numéro de séquenceSEQ\(= y\), - un segment
ACK: le client confirme avecACK= \(y + 1\) le numéro de séquence proposé (il attend l'octet \(y + 1\)).
Pendant la phase d'etablissement de connexion, le client et le serveur négocient la taille de segment maximale (MSS) en octets en indiquant chacun leur proposition dans le champ Option (une valeur typique est 1460B ce qui correspond à la taille maximale de la trame Ethernet 1500B, en-têtes IP et TCP inclus).
Après l'établissement de connexion les deux ectrémités peuvent envoyer des segments de données.
Le client ou le serveur peuvent fermer la connexion en envoyant un
segment en positionnant le flag FIN à 1. L'extrémité en face confirme
la demande avec un ACK et ferme la connexion dans la direction opposée
avec un segment FIN et ACK.
3.2.3 Transfert de données
Après l'établissement de la connexion, les deux extrémités peuvent envoyer des données (les principes de transfert de données sont présentés ici dans un seul sens) :
- Numéro de séquence
SEQ\(= x_1\) , \(x_1\) est le numéro du premier octet du champ de données, la longueur du champ de données est LEN = \(L_1\), - Le segment TCP
ACKpour le premier segment auraACK\(= x_1 + L_1\), - Le segment suivant aura
SEQ\(= x_1 + L_1\).
Exemple :
- 1er segment
SEQ=100, LEN=10 - 2ème segment
SEQ=110, LEN=20 - 3ème segment
SEQ=130, LEN=10 ACKpour le 1er segment:ACK=110ACKpour le 2e segment:ACK=130ACKpour le 3ème segment:ACK=140
Si les deux extrémités ont des données à envoyer dans des directions
opposées, les ACK ne sont pas envoyés dans des segments distincts,
mais directement dans les segments de données envoyés en retour
(piggybacking). Chaque segment contient donc un numéro de séquence
SEQ (pour l'envoi de données), ainsi qu'un numéro d'accusé de
réception ACK (pour la direction inverse).
Exemple :
- Envoyer segment
SEQ=100, ACK=1100, LEN=10 - Recevoir segment
SEQ=1100, ACK=110, LEN=50 - Envoyer segment
SEQ=110, ACK=1150, LEN=10 - Recevoir segment
SEQ=1150, ACK=120, LEN=50
3.2.4 Contrôle de flux
Le récepteur annonce la fenêtre courante à l'expéditeur dans le
champ fenêtre annoncée (qu'on désigne par WND plus bas).
L'expéditeur stocke cette valeur dans variable \(rwnd\) (received
window). Lors de la réception d'un segment avec ACK \(= j\) et \(k
=\) WND, l'expéditeur peut envoyer les données jusqu'à l'octet
numéro \(j + k - 1\).
Exemple : lors de la réception d'un segment avec ACK = 1000, WND =
3000, l'expéditeur peut envoyer
- 1er segment
SEQ=1000, LEN=1000 - 2ème segment
SEQ=2000, LEN=1000 - 3ème segment
SEQ=3000, LEN=1000
À la réception d'un segment avec WND=0, l'expéditeur ne peut plus
envoyer de segments de données. Si l'expéditeur doit envoyer des
données, il sonde le récepteur avec un segment contenant un octet de
données après la fin de la fenêtre (après l'expiration de la
temporisation Persist Timer).
Pourquoi la fenêtre annoncée WND est nécessaire ?
Parce qu'elle permet à l'expéditeur de ne pas envoyer plus de données que la place libre dans le tampon de réception.
Quelle est la taille maximale de \(rwnd\) ?
64KB (à moins d'utiliser l'option de la mise à l'échelle (RFC 1323) Qui permet l'augmentation de la taille maximale de la fenêtre).
3.2.5 Contrôle d'erreurs
TCP utilise le mécanisme de la fenêtre glissante avec la
retransmission continue en cas des segments perdus. L'expéditeur
détecte des pertes par temporisation : il associe une
temporisation RTO à chaque segment envoyé.
Quand la temporisation expire (timeout), il retransmet le premier segment non acquitté et réinitialise tous les temporisations associées à d'autres segments non acquittés (le comportement de la variante TCP Reno).
Les variantes antérieures (Tahoe) ne réinitialisent les temporisations qu'après la détection de perte (Tahoe implémente le protocole de retransmission continue - Go-Back-N). Comme les pertes isolées sont les plus probables, Reno ne retransmet que le premier segment.
- Retransmission rapide (Fast Retransmit)
- si 3
ACKdupliqués (la même valeur du champACK) sont reçus avant l'expiration de la temporisationRTO, l'expéditeur retransmet le premier segment non acquitté. La retransmission rapide accélère la récupération de pertes parce que le temps aller-retour necéssaire à la réception desACKdupliqués est plus court que leRTO.
Lors d'une réception d'un segment de données, un récepteur TCP peut :
- Envoyer un accusé de réception immédiatement,
- Attendre qu'il y ait un segment de données à envoyer (le mécanisme
de
Delayed ACK), ou - Attendre jusqu'à ce que les autres segments soient reçus, parce que les accusés de réception sont cumulatifs.
Le récepteur TCP doit immédiatement envoyer un ACK quand il reçoit un
segment hors séquence (il y a un gap dans la suite des données
reçues). Cet ACK sera un ACK dupliqué - il confirme les données
précédemment reçues.
L'attente d'un segment de données à envoyer dans la direction opposée
est limitée par la temporisation Delayed ACK (valeur typique de 200
ms) : si elle expire, un segment ACK sans données est envoyé.
3.2.6 Temporisation de retransmission
Lorsque TCP envoie un segment, il démarre une temporisation. Si le
délai expire avant la reception d'un ACK, il retransmet le segment non
acquitté (timeout). Comme cette temporisation doit être plus longue
que le temps d'aller-retour (RTT), TCP doit mesurer le RTT actuel.
Algorithme d'estimation du RTT.
RTT = 0, D = 3
RTO = RTT + 2 x D = 0 + 2 x 3 = 6 (for initial SYN)
RTT = RTT + g x (measured_RTT - RTT) (g = 1/8)
D = D + h x (|measured_RTT - RTT| - D) (h = 1/4)
RTO = RTT + 4 x D
If (a segment has been retransmitted after a timeout)
; apply exponential backoff
RTO = min(2 x RTO, 64 sec)
RTT and D are not updated
3.3 Contrôle de congestion TCP
La congestion arrive quand un hôte transmet des données avec un débit qui dépasse le capacité du réseau (en fait, la capacité d'une liaison appelée goulot d'étranglement sur la route entre la source et la destination). La congestion entraine des paquets perdus et une diminution du débit. Le contrôle de congestion vise à résoudre ces problèmes en adaptant le débit d'envoi des segments pour éviter la dégradation des performances.
3.3.1 Principes de contrôle de congestion
Une source TCP doit adapter le débit d'envoi de données à la capacité disponible sur un goulot d'étranglement. Le goulot d'étranglement est le lien sur la route entre la source et la destination sur lequel la connexion TCP obtient la plus petite capacité en compétition par rapport aux autres connexions qui partagent le lien. Une source TCP essaie de se rapprocher de cette capacité disponible sans la dépasser.
TCP utilise l'algorithme AIMD (Additive Increase Multiplicative Decrease) pour le contrôle de congestion :
- Augmenter le débit de façon additive (on ajoute une valeur constante à la fenêtre actuelle), si il n'y a pas de congestion,
- Diminuer le débit de manière multiplicative (on multiplie la fenêtre actuelle par une fraction) en cas de congestion.
TCP interprète des pertes comme le signal d'une congestion (on dépasse la capacité disponible).
Qu'est-ce qu'un goulot d'étranglement ?
Le lien sur lequel la connexion TCP obtient la plus petite capacité en concurrence avec les autres connexions qui partagent le lien.
Quel est l'impact d'un goulot d'étranglement pour une source TCP ?
Une source TCP doit adapter son débit d'envoi de données à la capacité disponible sur ce goulot d'étranglement.
Qu'est-ce le principe d'Additive Increase et quand est-il utilisé ?
Augmenter le débit de façon additive, quand il n'y a pas de congestion.
Qu'est-ce le principe de Multiplicative Decrease et quand est-il utilisé ?
Diminuer le débit de façon multiplicative en cas de congestion.
3.3.2 Fenêtre de congestion
TCP contrôle le débit d'envoi en ajustant la fenêtre de congestion (\(cwnd\)) comptée en octets.
La fenêtre d'envoi courante \(W\) est modulée par le mécanisme de contrôle de congestion à travers la variable \(cwnd\) et par le mécanisme de contrôle de flux à travers la variable \(rwnd\) (rappelez-vous que \(rwnd\) est la fenêtre annoncée correspondant à l'espace libre au niveau du tampon de réception en octets) :
$$W = min (cwnd, rwnd)$$.
Dans les exemples de contrôle de congestion qui suivent, nous supposons que \(rwnd\) est suffisamment grand pour que seul \(cwnd\) limite la fenêtre \(W\).
Qu'advient-il lorsque le récepteur annonce une fenêtre suffisamment grande ?
La fenêtre d'envoi est limitée par le mécanisme de contrôle de congestion.
3.3.3 Variantes de TCP
Du point de vue du contrôle de congestion, TCP a évolué au fil du temps. Plusieurs variantes ont été définies : Tahoe, Reno, New Reno, Vegas (NewReno est la variante la plus utilisée). Les variantes plus récentes incluent : BIC, CUBIC, Compound, et beaucoup d'autres. Tahoe est le variante la plus simple à deux états : Slow Start et Congestion Avoidance. Reno ajoute Fast Recovery.
Quels sont les états du contrôle de congestion définis par Tahoe ?
Slow Start et Congestion Avoidance.
Quels sont les états du contrôle de congestion définis par Reno ?
Slow Start, Congestion Avoidance, et Fast Recovery.
3.3.4 Slow Start
Algorithme de démarrage lent :
ssthresh = 64Ko cwnd = 1 x MSS (valeur initiale dépend de la mise en œuvre et il peut aller jusqu'à 3 MSS) augmenter cwnd de 1 MSS pour chaque ACK reçu ce qui se traduit par une augmentation exponentielle du nombre de segments : 1, 2, 4, 8 MSS etc. si la perte de segment détectée sur temporisation, appliquer décroissance multiplicative : ssthresh = cwnd/2 (mais pas moins de 2MSS) re-entrer en Slow Start si cwnd >= sshtresh, entrer en Congestion Avoidance
ssthresh correspond au seuil qu'une source TCP tente d'atteindre : TCP
sonde le réseau pour obtenir la capacité disponible sur le goulot
d'étranglement en augmentant progressivement la fenêtre de congestion
jusqu'à :
- une perte, on retourne en Slow Start, ou
cwnd\(>=\)sshtresh, on passe en Congestion Avoidance.
Comment fonctionne l'algorithme de Slow Start ?
Algorithme de Slow Start :
- Augmentation exponentielle (augmenter \(cwnd\) de 1 MSS pour chaque
ACK reçu) jusqu'à \(cwnd >= sshtresh\), puis
- entrer en Congestion Avoidance
- Si une perte, appliquer la décroissance multiplicative :
- \(ssthresh = cwnd/2\) (mais pas moins de 2 MSS)
- \(cwnd = 1\) MSS
- re-entrer en Slow Start
À quoi correspond le principe de décroissance multiplicative ?
Une façon de réduire la fenêtre de congestion après la détection d'une perte. Elle consiste à affecter à \(ssthresh\) la moitié de la valeur courante de la variable \(cwnd\).
Qu'est-ce le principe d'augmentation exponentielle ?
Une façon d'augmenter la fenêtre de congestion : ajouter 1 MSS à
\(cwnd\) pour chaque ACK reçu. Elle est utilisée en Slow Start
et en Fast Recovery.
3.3.5 Congestion Avoidance
Algorithme d'évitement de congestion :
appliquer Augmentation Additive : - ajouter 1 MSS à cwnd pour chaque fenêtre correctement transmise (on reçoit tous les ACK), ce qui entraîne une augmentation linéaire: 10, 11, 12 MSS etc. (adaptation de cwnd a lieu pour chaque ACK reçu : cwnd augmente de MSS × MSS/cwnd octets pour chaque ACK reçu). si la perte de segment sur timeout, appliquer Décroissance Multiplicative : - ssthresh = cwnd/2 (mais pas moins de 2MSS) - cwnd = 1 * MSS - enter Slow Start
Qu'est-ce qui se passe dans l'état de Congestion Avoidance ?
Algorithme de Congestion Avoidance :
- augmentation additive de cwnd :
- ajouter 1 MSS pour une fenêtre correctement transmise (en
fait: \(cwnd\) augmente de MSS x MSS/\(cwnd\) pour chaque
ACKreçu).
- ajouter 1 MSS pour une fenêtre correctement transmise (en
fait: \(cwnd\) augmente de MSS x MSS/\(cwnd\) pour chaque
- si une perte, ajuster les seuils :
- \(ssthresh = cwnd/2\) (mais pas moins de 2 MSS)
- entrer en Slow Start (\(cwnd = 1\) MSS)
A quoi correspond le principe d'augmentation additive ?
Une façon d'augmenter la fenêtre de congestion quand il n'y a pas
de pertes de segment. Elle consiste à ajouter 1 MSS à cwnd
lorsque TCP reçoit tous les ACKs pour toute la fenêtre : 5, 6, 7,
etc. (l'adaptation réele de \(cwnd\) a lieu pour chaque ACK reçu :
\(cwnd\) augmente de MSS x MSS/\(cwnd\)).
3.3.6 Fast Retransmit
Lorsque TCP reçoit 3 ACKs dupliqués, il les considère comme un signal d'une perte de segment et entre en Slow Start (Tahoe) ou en Fast Recovery (Reno, New Reno).
Qu'est-ce que Fast Retransmit ?
Lorsque TCP reçoit 3 ACK dupliqués, il les considère comme un signal d'une perte de segment et entre en Slow Start (Tahoe) ou en Fast Recovery (Reno, New Reno).
3.3.7 Fast Recovery
Algorithme de récupération rapide :
retransmettre segment manquant
appliquer Décroissance Multiplicative:
- ssthresh = cwnd/2 (mais pas moins de 2MSS)
gonfler cwnd pour compenser la détection de perte avec 3 ACK dupliqués :
- cwnd = cwnd + 3MSS
pour chaque ACK dupliqué :
- cwnd = cwnd + 1MSS
si ACK reçu pour le segment perdu
entrer en Congestion Avoidance avec cwnd = sstresh.
Pourquoi gonfler la \(cwnd\) de 3 MSS ?
Pour compenser 3 segments envoyés qui génèrent des ACK dupliqués après une perte.
3.4 UDP
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Source Port | Destination Port | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Length | Checksum | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | | | Data | | | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
L'en-tête d'un datagramme UDP a les champs suivants:
- Ports Source et Destination
- nombres sur 16 bits pour identifier le processus source et le processus de destination.
- Longueur
- longueur en octets de ce datagramme, y compris l'en-tête et les données. (Cela signifie que la valeur minimale de la longueur est de 8.)
- Checksum
- le complément à 1 de la somme des mots de 16 bits calculée sur le datagramme UDP avec la pseudo-en-tête ajouté au début. Le pseudo-en-tête joint à l'en-tête UDP contient l'adresse IP source, l'adresse IP de destination, le protocole, et la longueur UDP.
UDP n'offre ni la fiabilité ni le transfert ordonné à l'instar de TCP, mais il est plutôt adapté à un mode de fonctionnement requête-réponse. Si un datagramme UDP est reçu, la somme de contrôle indique l'absence d'erreurs de transmission. Les pertes peuvent se produire cependant et pourront être détectées par l'absence de la réponse.
3.5 NAT (Network Address Translation)
NAT fournit un moyen pour utiliser des adresses IP privées dans
une partie du réseau (Intranet). Un tel réseau utilise une adresse
IP publique et un ou plusieurs préfixes prises de la partie
réservée de l'espace d'adressage privé (10/8, 192.168/16,
etc.). Pour transmettre des paquets avec des adresses privées
comme les adresses sources, un routeur NAT maintient une table
pour Adresse et Port Forwarding:
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | private part | public part | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | private IP address, private port # | public port # | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Lorsque le routeur NAT reçoit un paquet IP avec :
- adresse IP source, le port source, par exemple
10.0.0.1et51234
il les remplace par :
- adresse IP de source publique, le port de source publique, par
exemple,
129.88.48.1et58765
Lorsque le routeur NAT reçoit le paquet de réponse avec :
- adresse IP de destination, port de destination, par exemple
129.88.48.1et58765
il recherche dans la table le port correspondant et remplace l'adresse de destination et le port de destination avec les valeurs de la table:
- adresse IP de destination privée, port de destination privée, par
exemple
10.0.0.1et51234
Il transmet le paquet à l'hôte de destination sur l'Intranet.
Pour atteindre les hôtes avec adresses privés sur un Intranet depuis l'Internet, des routeurs NAT utilisent la redirection de port (port forwarding) : ils maintiennent une table des ports associés à ses hôtes sur l'Intranet, ex.:
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | range | private IP address | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | 6800-6899 | 10.0.0.1 | | 6900-6999 | 10.0.0.2 | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Un hôte sur l'Internet envoie un paquet vers l'adresse publique et le
port de destination correspondant à une plage donnée, par exemple,
129.88.48.1 et 6910 pour atteindre l'hôte 10.0.0.2 (un service donné
pour l'atteindre a besoin de tourner sur le port choisi, par exemple,
le démon ssh sur le port 6910, si nous voulons nous connecter à
10.0.0.2 avec ssh).